Chapter 8 An introduction to regression
8.1 Introduction: models in scientific research
In science one of our main concerns is to develop models of the world, models that help us to understand the world a bit better or to predict how things will develop better. You can read more about modelling in scientific research here. Statistics provides a set of tools that help researchers build and test scientific models.
Our models can be simple. We can think that unemployment is a factor that may help us to understand why cities differ in their level of violent crime. We could express such a model like this:
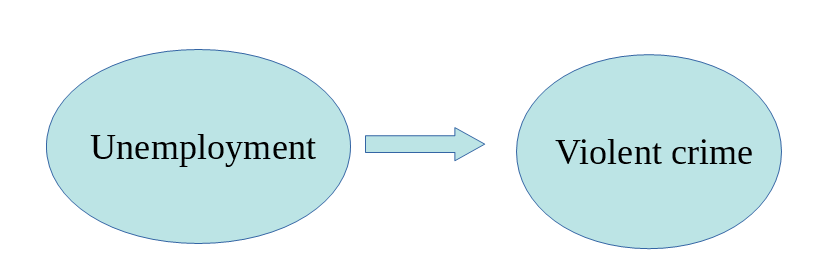
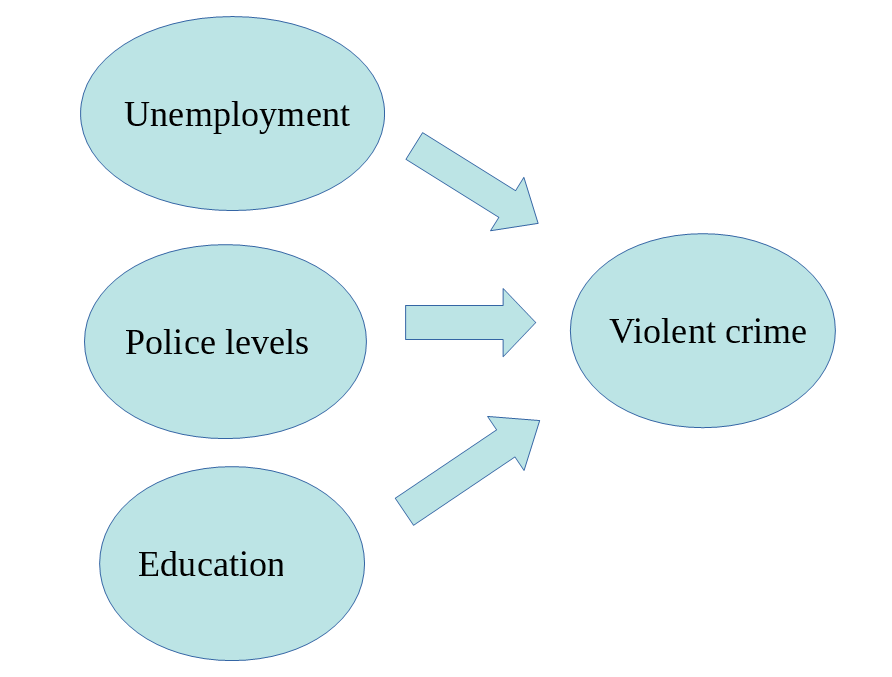
Surely we know the world is complex and likely there are other things that may help us to understand why some cities have more crime than others. So, we may want to have tools that allow us to examine such models. Like, for example, the one below:
In this session we are going to cover regression analysis or, rather, we are beginning to talk about regression modelling. This form of analysis has been one the main technique of data analysis in the social sciences for many years and it belongs to a family of techniques called generalised linear models. Regression is a flexible model that allows you to “explain” or “predict” a given outcome (Y), variously called your outcome, response or dependent variable, as a function of a number of what is variously called inputs, features or independent, explanatory, or predictive variables (X1, X2, X3, etc.). Following Gelman and Hill (2007), I will try to stick for the most part to the terms outputs and inputs.
Today we will cover something that is called linear regression or ordinary least squares regression (OLS), which is a technique that you use when you are interested in explaining variation in an interval level variable. First we will see how you can use regression analysis when you only have one input, like in our first model, and then we will move to situations when we have several explanatory variables or inputs, like in our second model.
We will use a new dataset today, specifically the data used by Patrick Sharkey and his colleagues to study the effect of non profit organisations in the levels of crime. In “Uneasy Peace” Prof Sharkey argues that one of the factors that contributed to the decline of crime from the 90s onwards was the role played by non profit community organisations to bring peace and services to deteriorated neighbourhoods. In this session we will use the replication data from one of the papers that Prof Sharkey published studying this question. We can find this data in the Harvard Dataverse. If you are interested in the specific study analysing this data you can find it here.
data_url <- "https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/46WIH0/ARS2VS"
sharkey <- read.table(url(data_url), sep = '\t',header = T)As before we create an object with the permanent url address and then we use a function to read the data into R. The data that can be saved using an api is in tab separated format. For this then we use the read.table function from base R. We pass two arguments to the function sep= '\t' is telling R this file is tab separated. The header = T function is telling R that is TRUE (T) that this file has a first row that acts as a header (this row has the name of the variables).
There are many more variables here that we are going to need, so let’s do some filtering and selection. Let’s just focus on a single year, 2012, the most recent in the dataset and just a few select variables.
library(dplyr)
df <- filter(sharkey, year == "2012")
df <- select(df, place_name, state_name, viol_r, black, lesshs, unemployed, fborn, incarceration, log_incarceraton, swornftime_r, log_viol_r, largest50)So now we have a more manageable data set that we can use for this session. The file includes a sample of 264 US cities (see place_name) across 44 of states:
##
## Alabama Alaska Arizona
## 4 1 9
## Arkansas California Colorado
## 1 65 10
## Connecticut District of Columbia Florida
## 5 1 18
## Georgia Idaho Illinois
## 2 1 8
## Indiana Iowa Kansas
## 3 3 5
## Louisiana Maryland Massachusetts
## 4 1 3
## Michigan Minnesota Mississippi
## 6 3 1
## Missouri Montana Nebraska
## 5 1 2
## Nevada New Hampshire New Jersey
## 3 1 4
## New Mexico New York North Carolina
## 1 5 9
## North Dakota Ohio Oklahoma
## 1 5 4
## Oregon Pennsylvania Rhode Island
## 4 4 1
## South Carolina South Dakota Tennessee
## 3 1 6
## Texas Utah Virginia
## 30 4 7
## Washington Wisconsin
## 6 3The variables we have extracted contain information on the demographic composition of those cities (percent black population, percent without high school degree, percent unemployed, percent foreign born), some criminal justice ones (incarceration rate and the rate of sworn full time police officers). We also have measures of the violence rate and a binary indicator that tell us if the city is one of the 50 largest in the country.
We are going to look at the relationship between violent crime with a variable measuring unemployment (unemployed). Let’s look at the violence rate:
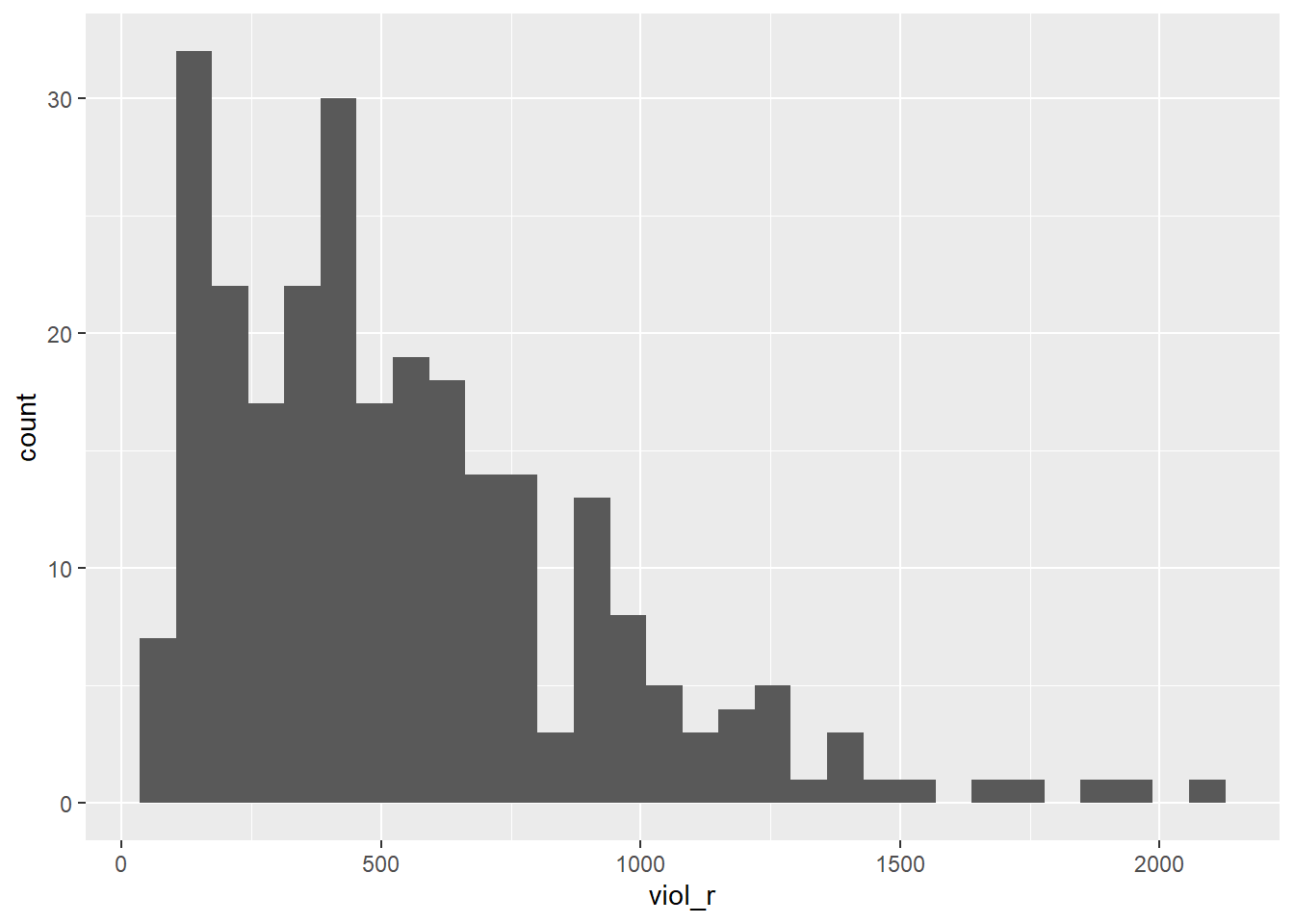
As you can see is skewed. Violence is our target variable, the one we want to better understand. You may remember from when we cover ANOVA that some times we have to make transformations to variables so that the assumptions of the models we use are better respected. We will discuss this a bit in greater depth later. For now, just trust us in that rather than using viol_r we are going to use the logarithmic transformation of the violence rate, log_viol_r.
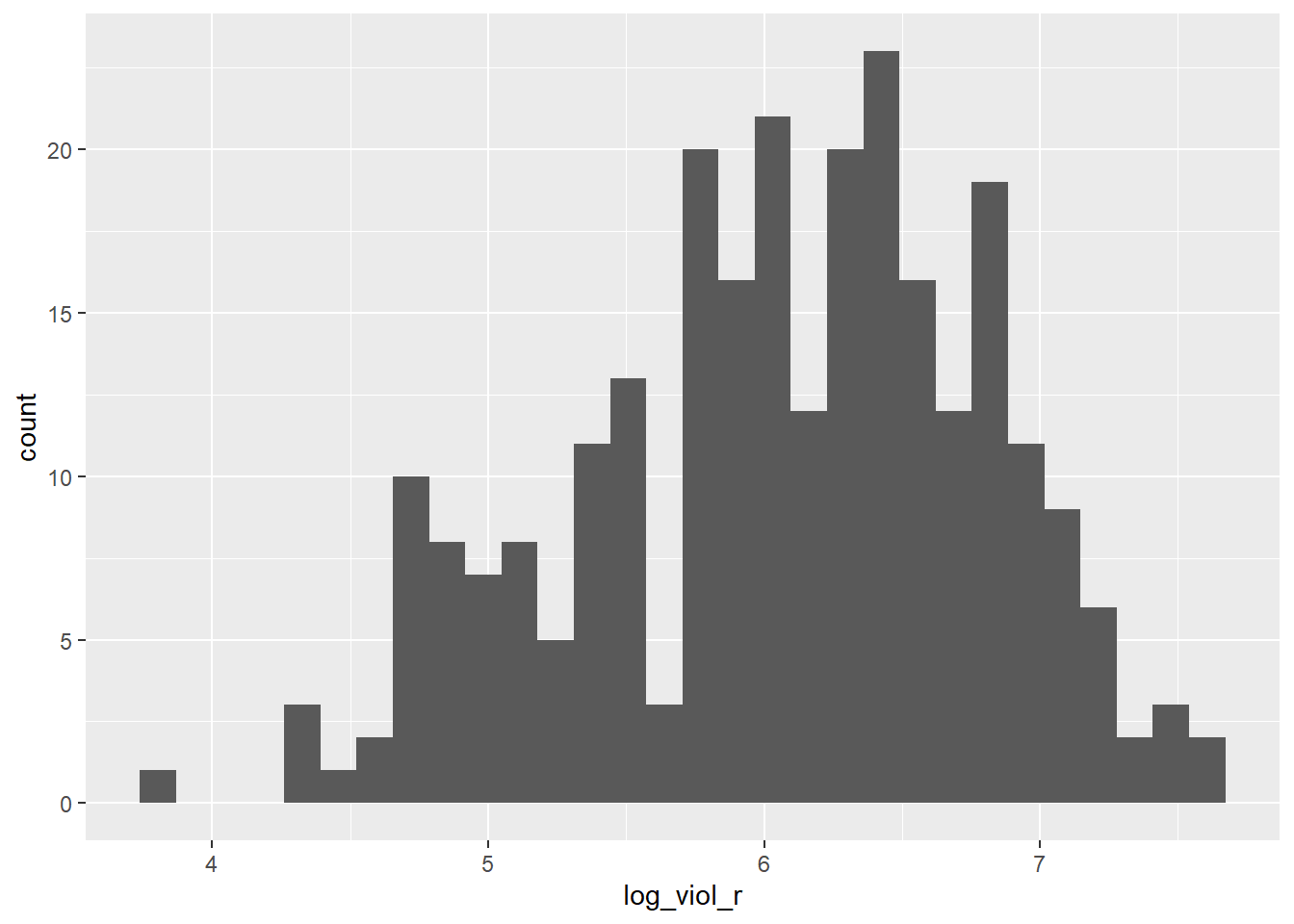
Let’s look at the scatterplot between the log of the violence rate and unemployment:
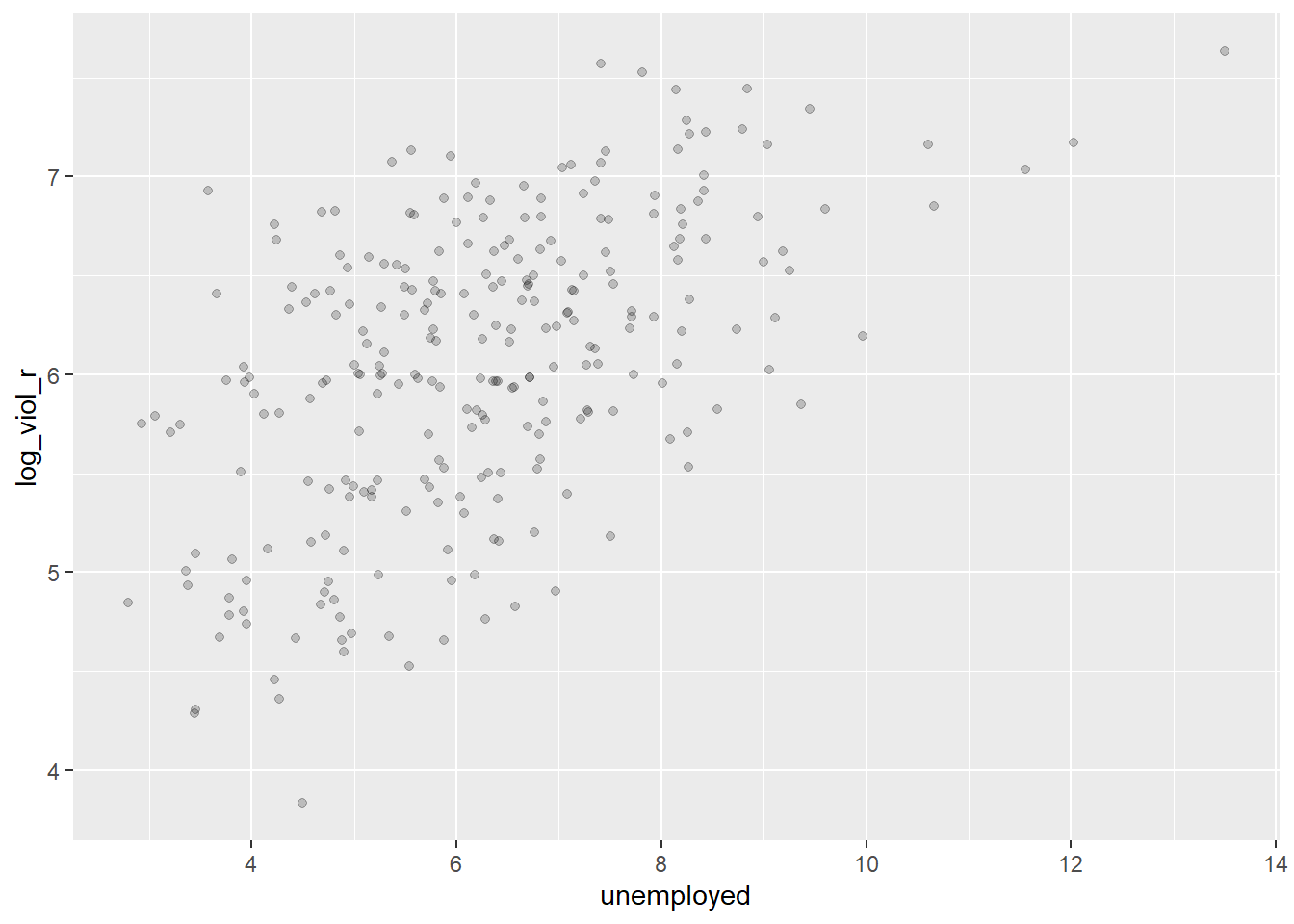
What do you think when looking at this scatterplot? Is there a relationship between violence and unemployment? Does it look as if cities that have a high score on the X axis (unemployment) also have a high score on the Y axis (violent crime)? It may be a bit hard to see but I would think there is certainly a trend.
8.2 Motivating regression
Now, imagine that we play a game. Imagine I have all the names of the cities in a hat, and I randomly take one of names from the hat. You’re sitting in the audience, and you have to guess the level of violence (log_viol_r) for that city. Imagine that I pay £150 to the student that gets the closest to the right value. What would you guess if you only have one guess and you knew (as we do) how the log of violent crime is distributed?
ggplot(df, aes(x = log_viol_r)) +
geom_density() +
geom_vline(xintercept = 6.061, linetype = "dashed", size = 1, color="red") +
ggtitle("Density estimate and mean of log violent crime rate")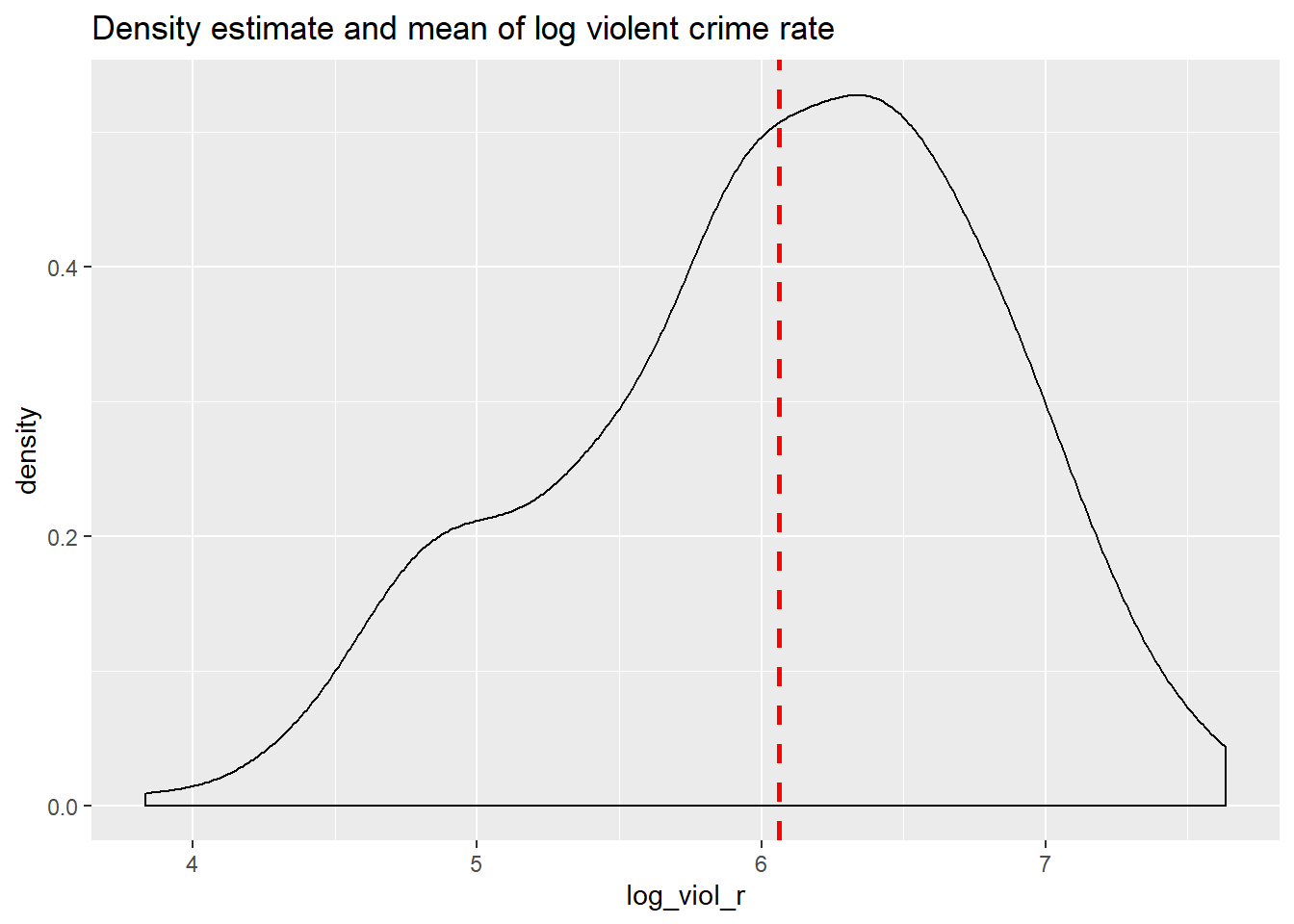
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.831 5.532 6.149 6.061 6.595 7.634If I only had one shot, I would go for the mean or the median (given the skew). Most of the cities have values clustered around those values, which is another way of saying they are bound to be not too far from them. It would be silly to say 4, for example, since there are very few cities with such low level of violence (as measured by log_viol_r).
Imagine, however, that now when I take the name of the city from the hat, you are also told how much unemployment there is in that city - so the value of the unemployed variable for the city that has been selected (for example 9). Imagine as well that you have the scatterplot that we produced earlier in front of you. Would you still go for the value of “six” (the mean) as your best guess for the value of the selected city?
I certainly would not go with the overall mean or median as my prediction any more. If somebody said to me, the value unemployed for the selected respondent is 9, I would be more inclined to guess the mean value for the cities with that level of unemployment (the conditional mean), rather than the overall mean across all the cities. Wouldn’t you?
If we plot the conditional means we can see that the mean log_viol_r for cities that report an unemployment of 9 is around 6.5. So you may be better off guessing that.
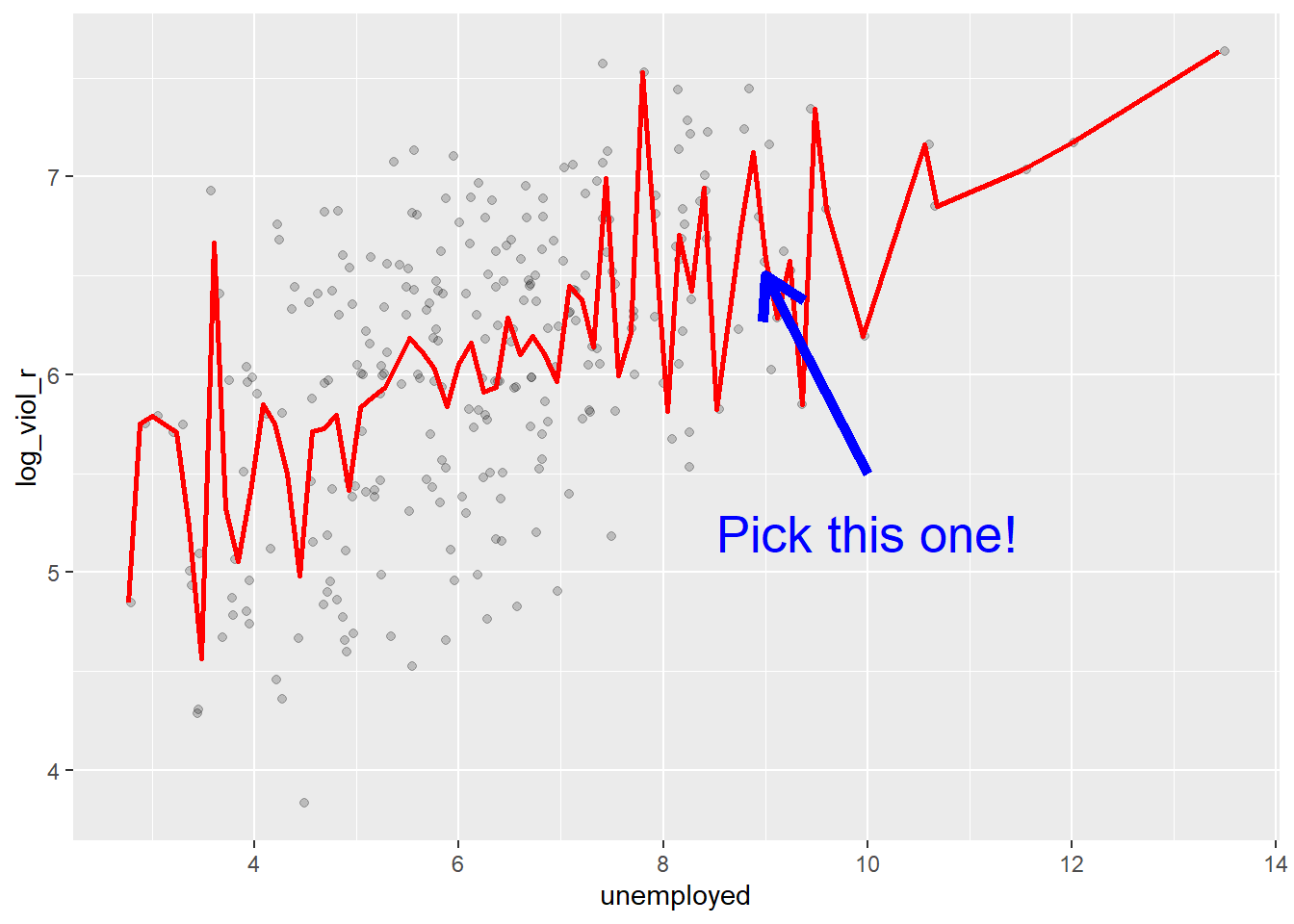
Linear regression tackles this problem using a slightly different approach. Rather than focusing on the conditional mean (smoothed or not), it draws a straight line that tries to capture the trend in the data. If we focus in the region of the scatterplot that are less sparse we see that this is an upward trend, suggesting that as the level of unemployment increases so does the level of violent crime.
Simple linear regression draws a single straight line of predicted values as the model for the data. This line would be a model, a simplification of the real world like any other model (e.g., a toy pistol, an architectural drawing, a subway map), that assumes that there is approximately a linear relationship between X and Y. Let’s draw the regression line:
ggplot(data = df, aes(x = unemployed, y = log_viol_r)) +
geom_point(alpha = .2, position = "jitter") +
geom_smooth(method = "lm", se = FALSE, color = "red", size = 1) 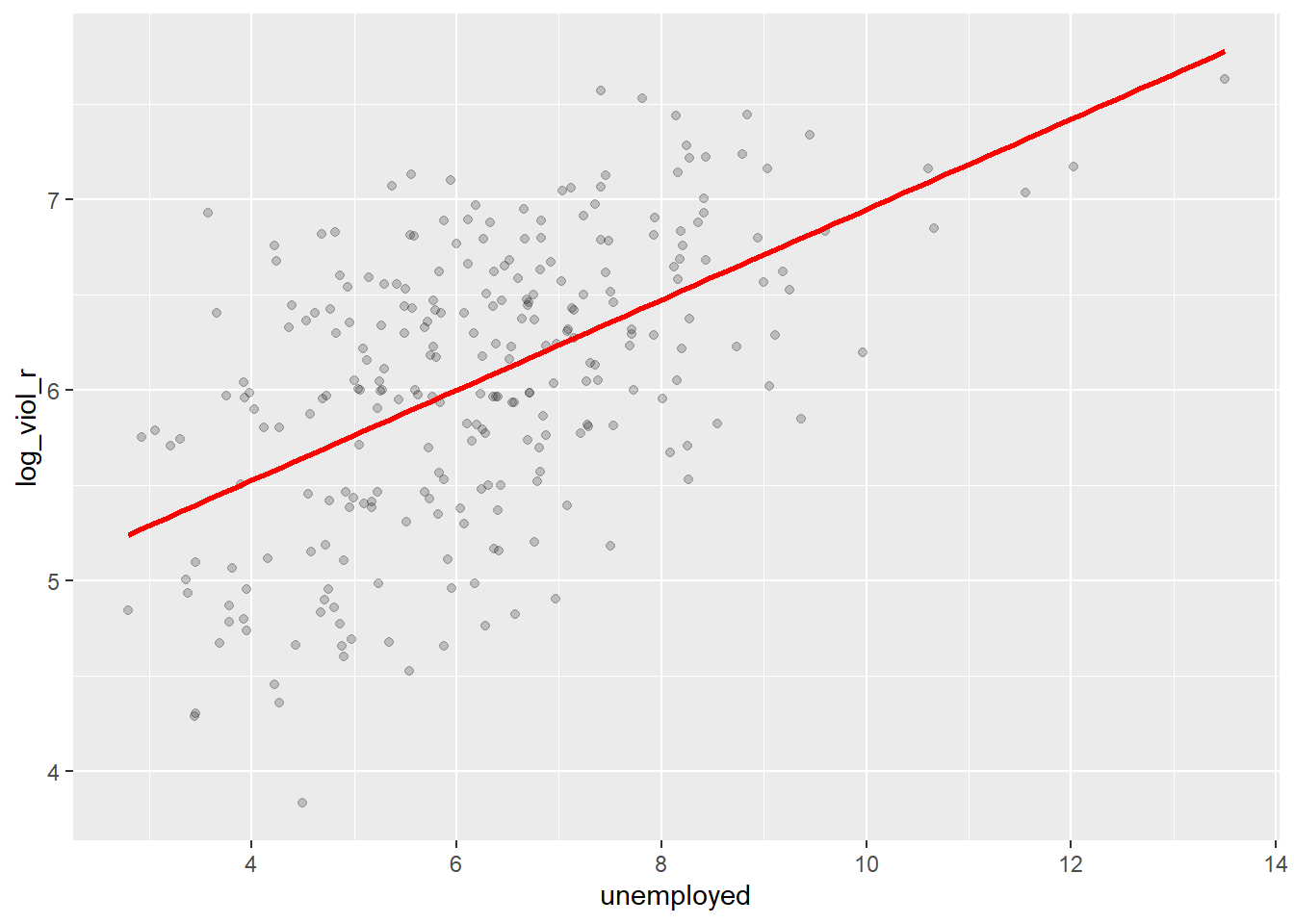
The geom_smooth function asks for a geom with the regression line, method=lm asks for the linear regression line, se=FALSE asks for just the line to be printed, the other arguments specify the colour and thickness of the line.
What that line is doing is giving you guesses (predictions) for the values of violent crime based in the information that we have about the level of unemployment. It gives you one possible guess for the value of violence for every possible value of unemployment and links them all together in a straight line.
Another way of thinking about this line is as the best possible summary of the cloud of points that are represented in the scatterplot (if we can assume that a straight line would do a good job doing this). If I were to tell you to draw a straight line that best represents this pattern of points the regression line would be the one that best does it (if certain assumptions are met).
The linear model then is a model that takes the form of the equation of a straight line through the data. The line does not go through all the points. In fact, you can see is a slightly less accurate representation than the (smoothed) conditional means:
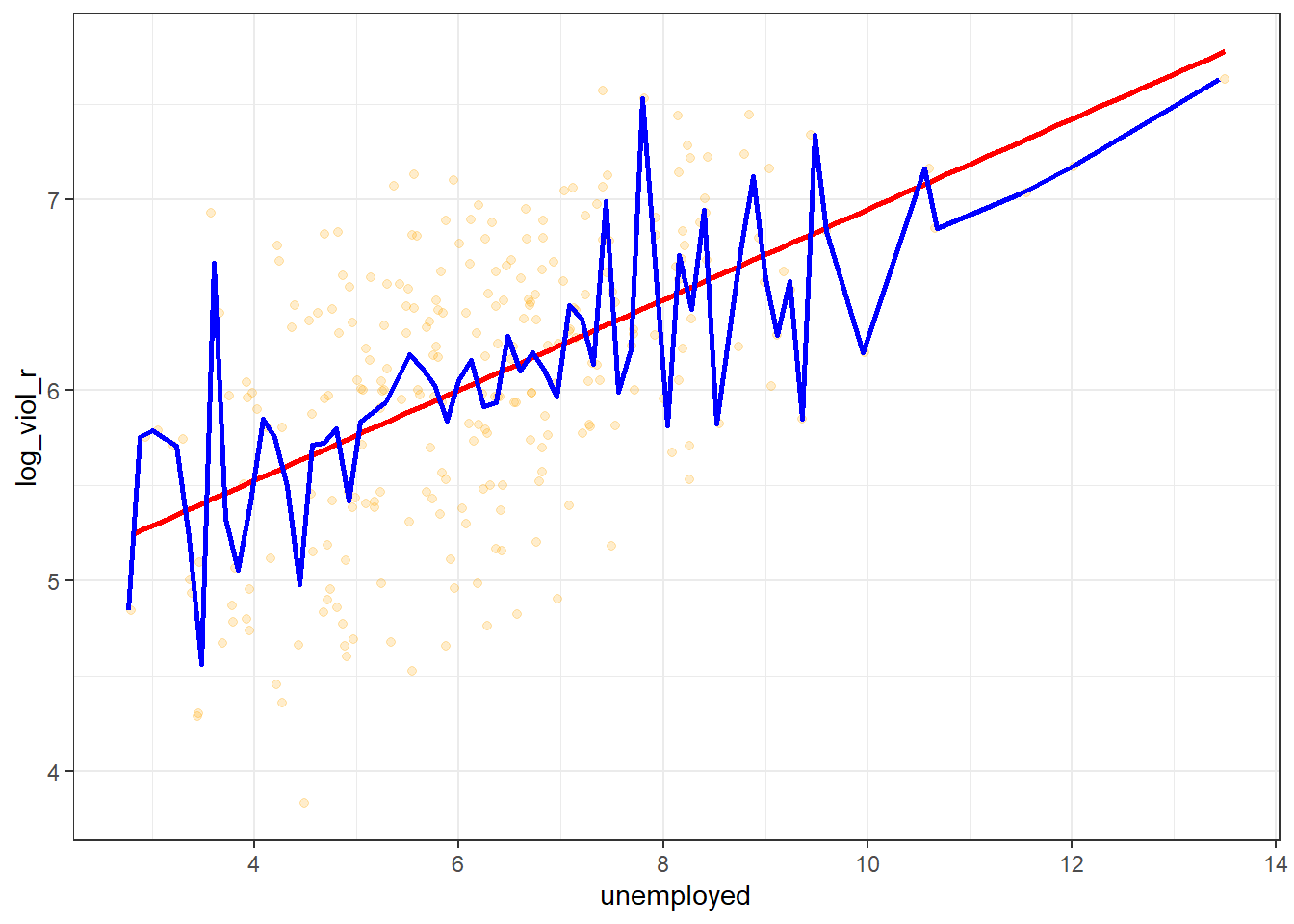
As De Veaux et al (2012: 179) highlight: “like all models of the real world, the line will be wrong, wrong in the sense that it can’t match reality exactly. But it can help us understand how the variables are associated”. A map is never a perfect representation of the world, the same happens with statistical models. Yet, as with maps, models can be helpful.
8.3 Fitting a simple regression model
In order to draw a regression line we need to know two things: (1) We need to know where the line begins, what is the value of Y (our dependent variable) when X (our independent variable) is 0, so that we have a point from which to start drawing the line. The technical name for this point is the intercept. (2) And we need to know what is the slope of that line, that is, how inclined the line is, the angle of the line.
If you recall from elementary algebra (and you may not), the equation for any straight line is: y = mx + b In statistics we use a slightly different notation, although the equation remains the same: y = b0 + b1x
We need the origin of the line (b0) and the slope of the line (b1). How does R get the intercept and the slope for the green line? How does R know where to draw this line? We need to estimate these parameters (or coefficients) from the data. How? We don’t have the time to get into these more mathematical details now. You should study the required reading to understand this (required means it is required, it is not optional)8. For now, suffice to say that for linear regression modes like the one we cover here, when drawing the line, R tries to minimise the distance from every point in the scatterplot to the regression line using a method called least squares estimation.
In order to fit the model we use the lm() function using the formula specification (Y ~ X). Typically you want to store your regression model in a “variable”, let’s call it fit_1:
You will see in your R Studio global environment space that there is a new object called fit_1 with 12 elements on it. We can get a sense for what this object is and includes using the functions we introduced in Week 1:
## [1] "lm"## $names
## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"
##
## $class
## [1] "lm"R is telling us that this is an object of class lm and that it includes a number of attributes. One of the beauties of R is that you are producing all the results from running the model, putting them in an object, and then giving you the opportunity for using them later on. If you want to simply see the basic results from running the model you can use the summary() function.
##
## Call:
## lm(formula = log_viol_r ~ unemployed, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.81195 -0.44612 0.06817 0.45424 1.50438
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.57817 0.14899 30.73 <2e-16 ***
## unemployed 0.23710 0.02302 10.30 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.6254 on 262 degrees of freedom
## Multiple R-squared: 0.2882, Adjusted R-squared: 0.2855
## F-statistic: 106.1 on 1 and 262 DF, p-value: < 2.2e-16Or if you prefer more parsimonious presentation you could use the display() function of the arm package:
## lm(formula = log_viol_r ~ unemployed, data = df)
## coef.est coef.se
## (Intercept) 4.58 0.15
## unemployed 0.24 0.02
## ---
## n = 264, k = 2
## residual sd = 0.63, R-Squared = 0.29For now I just want you to focus on the numbers in the “Estimate” column. The value of 4.58 estimated for the intercept is the “predicted” value for Y when X equals zero. This is the predicted value of the violence score when the level of unemployment is zero.
We then need the b1 regression coefficient for for our independent variable, the value that will shape the slope in this scenario. This value is 0.24. This estimated regression coefficient for our independent variable has a convenient interpretation. When the value is positive, it tells us that for every one unit increase in X there is a b1 increase on Y. If the coefficient is negative then it represents a decrease on Y. Here, we can read it as “for every one unit increase in the percentage of people unemployed, there is a 0.24 unit increase in the logarithm of the violence rate.”
Knowing these two parameters not only allows us to draw the line, we can also solve for any given value of X. Let’s go back to our guess-the-violence game. Imagine I tell you the level of unemployment is 4. What would be your best bet now? We can simply go back to our regression line equation and insert the estimated parameters:
y = b0 + b1x
y = 4.58 + 0.24 (4)
y = .1031
Or if you don’t want to do the calculation yourself, you can use the predict function (differences are due to rounding error):
## 1
## 5.526564This is the expected value of Y, log of the violence rate, when X, unemployment is 5% of the population according to our model (according to our simplification of the real world, our simplification of the whole cloud of points into just one straight line). Look back at the scatterplot we produced earlier with the green line. Does it look as if the green line when X is 4 corresponds to a value of Y of 5.5?
8.4 Residuals revisited: R squared
In the output when we run the model above we saw there was something called the residuals. The residuals (in regression) are the differences between the observed values of Y for each case minus the predicted or expected value of Y, in other words the distances between each point in the dataset and the regression line (see the visual example below).
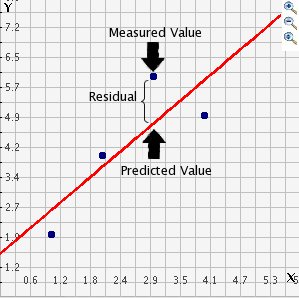
drawing
You see that we have our line, which is our predicted values, and then we have the black dots which are our actually observed values. The distance between them is essentially the amount by which we were wrong, and all these distances between observed and predicted values are our residuals. Least square estimation, the “machine” we use to build the regression line, essentially aims to reduce the squared average of all these distances: that’s how it draws the line.
Why do we have residuals? Well, think about it. The fact that the line is not a perfect representation of the cloud of points makes sense, doesn’t it? You cannot predict perfectly what the value of Y is for every city just by looking ONLY at unemployment! This line only uses information regarding unemployment. This means that there’s bound to be some difference between our predicted level of violence given our knowledge of unemployment (the regression line) and the actual level of violence (the actual location of the points in the scatterplot). There are other things that matter not being taken into account by our model to predict the values of Y. There are other things that surely matter in terms of understanding violence. And then, of course, we have measurement error and other forms of noise.
We can re-write our equation like this if we want to represent each value of Y (rather than the predicted value of Y) then: y = b0 + b1x + residuals
The residuals capture how much variation is unexplained, how much we still have to learn if we want to understand variation in Y. A good model tries to maximise explained variation and reduce the magnitude of the residuals.
We can use information from the residuals to produce a measure of effect size, of how good our model is in predicting variation in our dependent variables. Remember our game where we try to guess violence (Y)? If we did not have any information about X our best bet for Y would be the mean of Y. The regression line aims to improve that prediction. By knowing the values of X we can build a regression line that aims to get us closer to the actual values of Y.
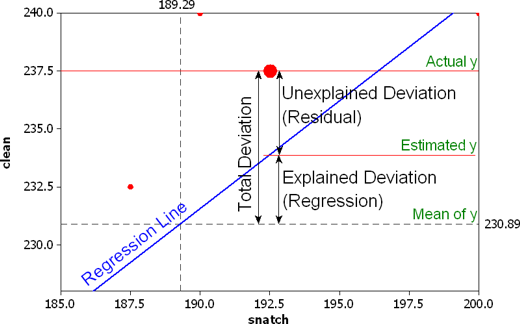
The distance between the mean (our best guess without any other piece of information) and the observed value of Y is what we call the total variation. The residual is the difference between our predicted value of Y and the observed value of Y. This is what we cannot explain (i.e, variation in Y that is unexplained). The difference between the mean value of Y and the expected value of Y (the value given by our regression line) is how much better we are doing with our prediction by using information about X (i.e., in our previous example it would be variation in Y that can be explained by knowing about unemployment). How much closer the regression line gets us to the observed values. We can then contrast these two different sources of variation (explained and unexplained) to produce a single measure of how good our model is. The formula is as follows:

formula
All this formula is doing is taking a ratio of the explained variation (the squared differences between the regression line and the mean of Y for each observation) by the total variation (the squared differences of the observed values of Y for each observation from the mean of Y). This gives us a measure of the percentage of variation in Y that is “explained” by X. If this sounds familiar is because it is a measure similar to eta squared in ANOVA that we cover in an earlier session.
As then we can take this value as a measure of the strength of our model. If you look at the R output you will see that the R2 for our model was .29 (look at the multiple R square value in the output) . We can say that our model explains 29% of the variance in the fear of violent crime measure.
#As an aside, and to continue emphasising your appreciation of the object oriented nature of R, when we run the summary() function we are simply generating a list object of the class summary.lm.
attributes(summary(fit_1))## $names
## [1] "call" "terms" "residuals" "coefficients"
## [5] "aliased" "sigma" "df" "r.squared"
## [9] "adj.r.squared" "fstatistic" "cov.unscaled"
##
## $class
## [1] "summary.lm"#This means that we can access its elements if so we wish. So, for example, to obtain just the R Squared, we could ask for:
summary(fit_1)$r.squared## [1] 0.2881989Knowing how to interpret this is important. R^2 ranges from 0 to 1. The greater it is the more powerful our model is, the more explaining we are doing, the better we are able to account for variation in our outcome Y with our input. In other words, the stronger the relationship is between Y and X. As with all the other measures of effect size interpretation is a matter of judgement. You are advised to see what other researchers report in relation to the particular outcome that you may be exploring.This is a reasonable explanation of how to interpret R-Squared.
Weisburd and Britt (2009: 437) suggest that in criminal justice you rarely see values for R^2 greater than .40. Thus, if your R^2 is larger than .40, you can assume you have a powerful model. When, on the other hand, R^2 is lower than .15 or .2 the model is likely to be viewed as relatively weak. Our observed r squared here is not too bad. There is considerably room for improvement if we want to develop a better model to explain violence 9. In any case, many people would argue that R^2 is a bit overrated. You need to be aware of what it measures and the context in which you are using it. Read here for some additional detail.
8.5 Inference with regression
In real applications, we have access to a set of observations from which we can compute the least squares line, but the population regression line is unobserved. So our regression line is one of many that could be estimated. A different sample would produce a different regression line. The same sort of ideas that we introduced when discussing the estimation of sample means or proportions also apply here. if we estimate b0 and b1 from a particular sample, then our estimates won’t be exactly equal to b0 and b1 in the population. But if we could average the estimates obtained over a very large number of data sets, the average of these estimates would equal the coefficients of the regression line in the population.
In the same way that we can compute the standard error when estimating the mean and explained in Week 5, we can compute standard errors for the regression coefficients to quantify our uncertainty about these estimates. These standard errors can in turn be used to produce confidence intervals. This would require us to assume that the residuals are normally distributed. As seen in the image, and for a simple regression model, you are assuming that the values of Y are approximately normally distributed for each level of X:

normalityresiduals
In those circumstances we can trust the confidence intervals that we can draw around the regression line as in the image below:
estimated
The dark-blue line marks the best fit. The two dark-pink lines mark the limits of the confidence interval. The light-pink lines show the sampling distributions around each of the confidence-interval limits (the many regression lines that would result from repeated sampling); notice that the best-fit line falls at the extreme of each sampling distribution.
You can also then perform standard hypothesis test on the coefficients. As we saw before when summarising the model, R will compute the standard errors and a t test for each of the coefficients.
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.5781742 0.14898596 30.72890 7.474077e-89
## unemployed 0.2370975 0.02302022 10.29953 4.145166e-21In our example, we can see that the coefficient for our predictor here is statistically significant.
We can also obtain confidence intervals for the estimated coefficients using the confint() function:
## 2.5 % 97.5 %
## (Intercept) 4.2848120 4.8715365
## unemployed 0.1917693 0.2824257This blog post provides a nice animation of the confidence interval and hypothesis testing.
8.6 Fitting regression with categorical predictors
So far we have explained regression using a numeric input. It turns out we can also use regression with categorical explanatory variables. It is quite straightforward to run it.
We have one categorical variable in the dataset, largest50, identifying whether the city is one of the 50 largest in the country.
##
## 0 1
## 216 48## [1] "numeric"This variable is however stored in a numeric vector. We may want to change this to reflect the fact it is actually categorical.
## [1] "factor"Let’s rename the levels. In previous sessions we have illustrated how to do that with base R functions. Here we introduce a new package forcats that is worth considering when doing any work with factor variables. You can read more about it here.
##
## No Yes
## 216 48We can explore if particularly large cities have higher rates of violence (remember a rate controls for population size, so if this were to be significant it would be telling us that it’s not just because there is more people in them!). This is how you would express the model:
Notice that there is nothing different in how we ask for the model. And see below the regression line:
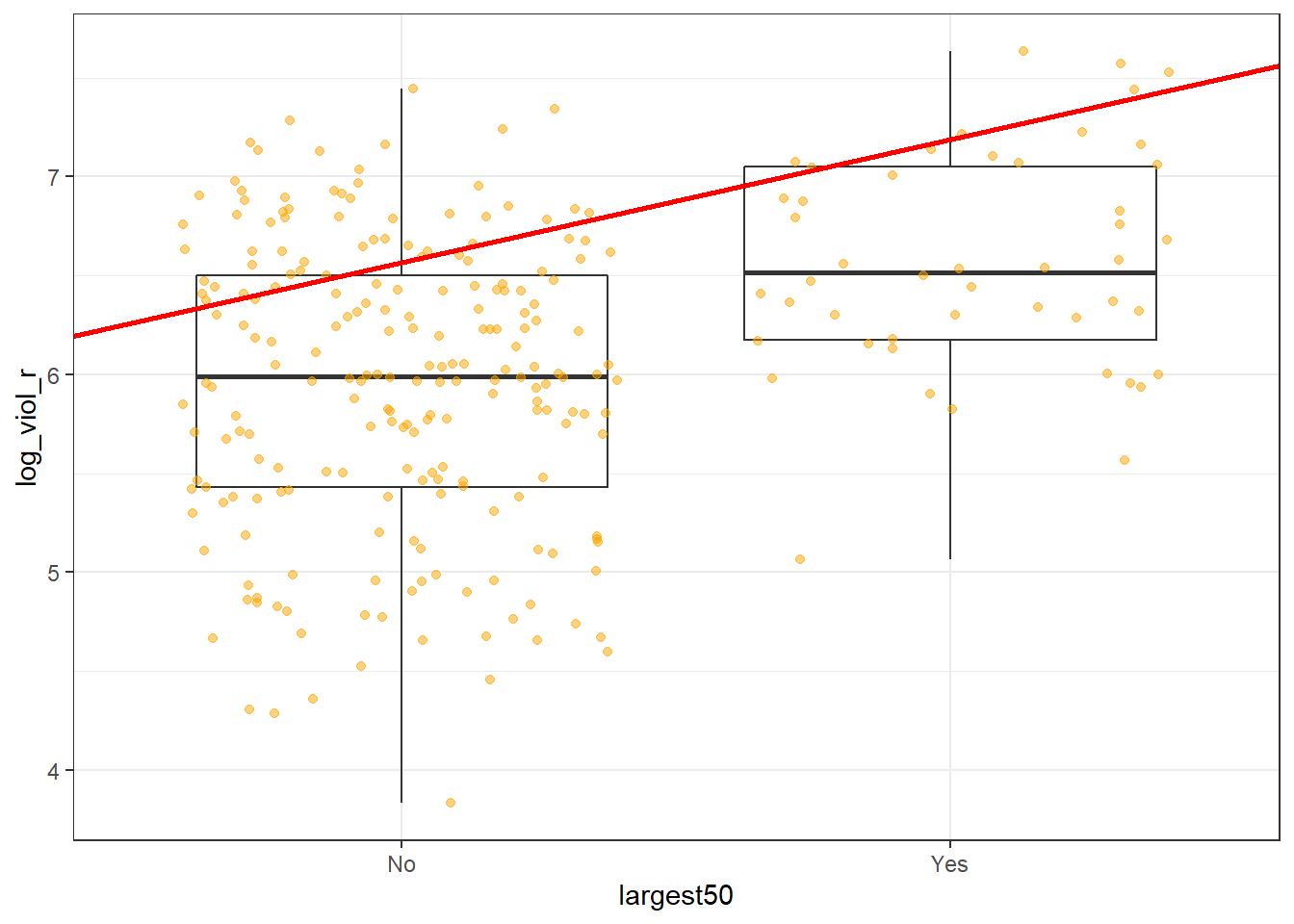
Although in the plot we still see a line, what we are really estimating here is the average of log_viol_r for each of the two categories.
Let’s have a look at the results:
##
## Call:
## lm(formula = log_viol_r ~ largest50, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.11616 -0.48286 0.02965 0.51523 1.49789
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.94763 0.04771 124.661 < 2e-16 ***
## largest50Yes 0.62114 0.11189 5.551 6.94e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7012 on 262 degrees of freedom
## Multiple R-squared: 0.1052, Adjusted R-squared: 0.1018
## F-statistic: 30.82 on 1 and 262 DF, p-value: 6.943e-08As you will see the output does not look too different. But notice that in the print out you see how the row with the coefficient and other values for our input variable largest50 we see that R is printing largest50Yes. What does this mean?
Remember week 6 and t tests? It turns out that a linear regression model with just one dichotomous categorical predictor is just the equivalent of a t test. When you only have one predictor the value of the intercept is the mean value of what we call the reference category and the coefficient for the slope tells you how much higher (if it is positive) or how much lower (if it is negative) is the mean value for the other category in your factor.
The reference category is the one for which R does not print the level next to the name of the variable for which it gives you the regression coefficient. Here we see that the named level is “Yes” (largest50Yes). That’s telling you that the reference category here is “No”. Therefore the Y intercept in this case is the mean value of violence for cities that are not the largest in the country, whereas the coefficient for the slope is telling you how much higher the mean value is for the largest cities in the country. Don’t believe me?
## [1] 5.947628#Compute the difference between the two means
mean(df$log_viol_r[df$largest50 == "Yes"], na.rm=TRUE) - mean(df$log_viol_r[df$largest50 == "No"], na.rm=TRUE)## [1] 0.6211428So, to reiterate, for a single binary predictor, the coefficient is nothing else than the difference between the mean of the two levels in your factor variable, between the averages in your two groups.
With categorical variables encoded as factors you always have a situation like this: a reference category and then as many additional coefficients as there are additional levels in your categorical variable. Each of these additional categories is input into the model as “dummy” variables. Here our categorical variable has two levels, thus we have only one dummy variable. There will always be one fewer dummy variable than the number of levels. The level with no dummy variable, females in this example, is known as the reference category or the baseline.
It turns out then that the regression table is printing out for us a t test of statistical significance for every input in the model. If we look at the table above this t value is 5.55 and the p value associated with it is near 0. This is indeed considerably lower than the conventional significance level of 0.05. So we could conclude that the probability of obtaining this value if the null hypothesis is true is very low. However, the observed r squared is also kind of poor. Read this to understand a bit more this phenomenon of low p, but also low r-squared.
If rather than a binary explanatory variable, you had a factor with five levels. Then if you were to run a regression model this would result in a model with 4 dummy variables. The coefficient of each of these dummies would be telling you how much higher or lower (if the sign were negative) was the level of violence for each of the levels for which you have a dummy compared to your reference category or baseline. One thing that is important to keep in mind is that R by default will use as the baseline category the first level in your factor.
## [1] "No" "Yes"In our case you can see “No” is listed first. Keep in mind for your assignment that levels in factors are often alphabetically listed, not in a particularly meaningful or useful way. If you want to change this you may need to reorder the levels. See here how to do this.
8.7 Motivating multiple regression
So we have seen that our models with just one predictor are not terribly powerful. Partly that’s due to the fact that they are not properly specified, they do not include a solid set of good predictor variables that can help us to explain variation in our response variable. We can build better models by expanding the number of predictors (although keep in mind you should also aim to build models as parsimonious as possible).
Another reason why it is important to think about additional variables in your model is to control for spurious correlations (although here you may also want to use your common sense when selecting your variables!). You must have heard before that correlation does not equal causation. Just because two things are associated we cannot assume that one is the cause for the other. Typically we see how the pilots switch the secure the belt button when there is turbulence. These two things are associated, they tend to come together. But the pilots are not causing the turbulences by pressing a switch! The world is full of spurious correlations, associations between two variables that should not be taking too seriously. You can explore a few here. It’s funny.
Looking only at covariation between pair of variables can be misleading. It may lead you to conclude that a relationship is more important than it really is. This is no trivial matter, but one of the most important ones we confront in research and policy10.
It’s not an exaggeration to say that most quantitative explanatory research is about trying to control for the presence of confounders, variables that may explain explain away observed associations. Think about any criminology question: Does marriage reduces crime? Or is it that people that get married are different from those that don’t (and are those pre-existing differences that are associated with less crime)? Do gangs lead to more crime? Or is it that young people that join gangs are more likely to be offenders to start with? Are the police being racist when they stop and search more members of ethnic minorities? Or is it that there are other factors (i.e., offending, area of residence, time spent in the street) that, once controlled, would mean there is no ethnic dis-proportionality in stop and searches? Does a particular program reduces crime? Or is the observed change due to something else?
These things also matter for policy. Wilson and Kelling, for example, argued that signs of incivility (or antisocial behaviour) in a community lead to more serious forms of crime later on as people withdraw to the safety of their homes when they see those signs of incivilities and this leads to a reduction in informal mechanisms of social control. All the policies to tackle antisocial behaviour in this country are very much informed by this model and were heavily influenced by broken windows theory.
But is the model right? Sampson and Raudenbush argue it is not entirely correct. They argue, and tried to show, that there are other confounding (poverty, collective efficacy) factors that explain the association of signs of incivility and more serious crime. In other words, the reason why you see antisocial behaviour in the same communities that you see crime is because other structural factors explain both of those outcomes. They also argue that perceptions of antisocial behaviour are not just produced by observed antisocial behaviour but also by stereotypes about social class and race. If you believe them, then the policy implications are that only tackling antisocial behaviour won’t help you to reduce crime (as Wilson and Kelling have argued) . So as you can see this stuff matters for policy not just for theory.
Multiple regression is one way of checking the relevance of competing explanations. You could set up a model where you try to predict crime levels with an indicator of broken windows and an indicator of structural disadvantage. If after controlling for structural disadvantage you see that the regression coefficient for broken windows is still significant you may be into something, particularly if the estimated effect is still large. If, on the other hand, the t test for the regression coefficient of your broken windows variable is no longer significant, then you may be tempted to think that perhaps Sampson and Raudenbush were into something.
8.8 Fitting and interpreting a multiple regression model
It could not be any easier to fit a multiple regression model. You simply modify the formula in the lm() function by adding terms for the additional inputs.
##
## Call:
## lm(formula = log_viol_r ~ unemployed + largest50, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.7338 -0.4047 -0.0189 0.4531 1.5726
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.54871 0.14101 32.258 < 2e-16 ***
## unemployed 0.22625 0.02186 10.351 < 2e-16 ***
## largest50Yes 0.53495 0.09476 5.645 4.29e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5915 on 261 degrees of freedom
## Multiple R-squared: 0.3657, Adjusted R-squared: 0.3608
## F-statistic: 75.23 on 2 and 261 DF, p-value: < 2.2e-16With more than one input, you need to ask yourself whether all of the regression coefficients are zero. This hypothesis is tested with a F test, similar to the one we described when describing ANOVA (in fact ANOVA is just a special case of regression). Again we are assuming the residuals are normally distributed, though with large samples the F statistics approximates the F distribution.
You see the F test printed at the bottom of the summary output and the associated p value, which in this case is way below the conventional .05 that we use to declare statistical significance and reject the null hypothesis. At least one of our inputs must be related to our response variable.
Notice that the table printed also reports a t test for each of the predictors. These are testing whether each of these predictors is associated with the response variable when adjusting for the other variables in the model. They report the “partial effect of adding that variable to the model” (James et al. 2014: 77). In this case we can see that both variables seem to be significantly associated with the response variable.
If we look at the r squared we can now see that it is higher than before. This quantity, r squared, will always increase as a consequence of adding new variables, even if the new variables added are weakly related to the response variable. But the increase we are observing suggests that adding these two variables results in a substantially improvement to our previous model.
We see that the coefficients for the predictors change very little, it goes down a bit for unemployed and it goes down somehow more for largest50. But their interpretation now changes. A common interpretation is that now the regression for each variable tells you about changes in Y related to that variable when the other variables in the model are held constant. So, for example, you could say the coefficient for unemployed represents the increase in the log of the violence rate for every one-unit increase in the measure of unemployment when holding all other variables in the model constant (in this case that refers to holding constant largest50). But this terminology can be a bit misleading.
Other interpretations are also possible and are more generalizable. Gelman and Hill (2007: p. 34) emphasise what they call the predictive interpretation that considers how “the outcome variable differs, on average, when comparing two groups of units that differ by 1 in the relevant predictor while being identical in all the other predictors”. So if you’re regressing y on u and v, the coefficient of u is the average difference in y per difference in u, comparing pairs of items that differ in u but are identical in v.
So, for example, in this case we could say that comparing respondents who have the same level of unemployment but who differed in whether they are one of the largest cities or not, the model predicts a expected difference of .53 in their violent crime measure. And that cities with the same size category, but that differ by one percent point in unemployment, we would expect to see a difference of 0.23 in their violent crime measure. So we are interpreting the regression slopes as comparisons of observation that differ in one predictor while being at the same levels of the other predictors.
As you can see, interpreting regression coefficients can be kind of tricky. The relationship between the response y and any one explanatory variable can change greatly depending on what other explanatory variables are present in the model.
For example, if you contrast this model with the one we run with only largest50 as a predictor you will notice the intercept has changed. You cannot longer read the intercept as the mean value of violence for smaller cities. Adding predictors to the model changes their meaning. Now the intercept index the value of violence for smaller cities that, in addition, score 0 in unemployed. In this case you don’t have cases that meet this condition (equal zero in all your predictors). More often than not, then, there is not much value in bothering to interpret the intercept because if does not represent a real observation in your sample.
Something you need to be particularly careful about is to interpret the coefficients in a causal manner. At least your data come from an experiment this is unlikely to be helpful. With observational data regression coefficients should not be read as indexing causal relations. This sort of textbook warning is, however, often neglectfully ignored by professional researchers. Often authors carefully draw sharp distinctions between causal and correlational claims when discussing their data analysis, but then interpret the correlational patterns in a totally causal way in their conclusion section. This is what is called the causation or causal creep. Beware. Don’t do this tempting as it may be.
Comparing the simple models with this more complex model we could say that adjusting for largest50 does not change much the impact of unemployed in violence and almost the same can be said about the effect of largest50 when holding unemployed fixed.
8.9 Presenting your regression results.
Communicating your results in a clear manner is incredibly important. We have seen the tabular results produced by R. If you want to use them in a paper you may need to do some tidying up of those results. There are a number of packages (textreg, stargazer) that automatise that process. They take your lm objects and produce tables that you can put straight away in your reports or papers. One popular trend in presenting results is the coefficient plot as an alternative to the table of regression coefficients. There are various ways of producing coefficient plots with R for a variety of models. See here and here, for example.
We are going to use instead the plot_model() function of the sjPlot package, that makes it easier to produce this sort of plots. You can find a more detailed tutorial about this function here. See below for an example:
Let’s try with a more complex example:
fit_4 <- lm(log_viol_r ~ unemployed + largest50 + black + fborn + log_incarceraton, data=df)
plot_model(fit_4)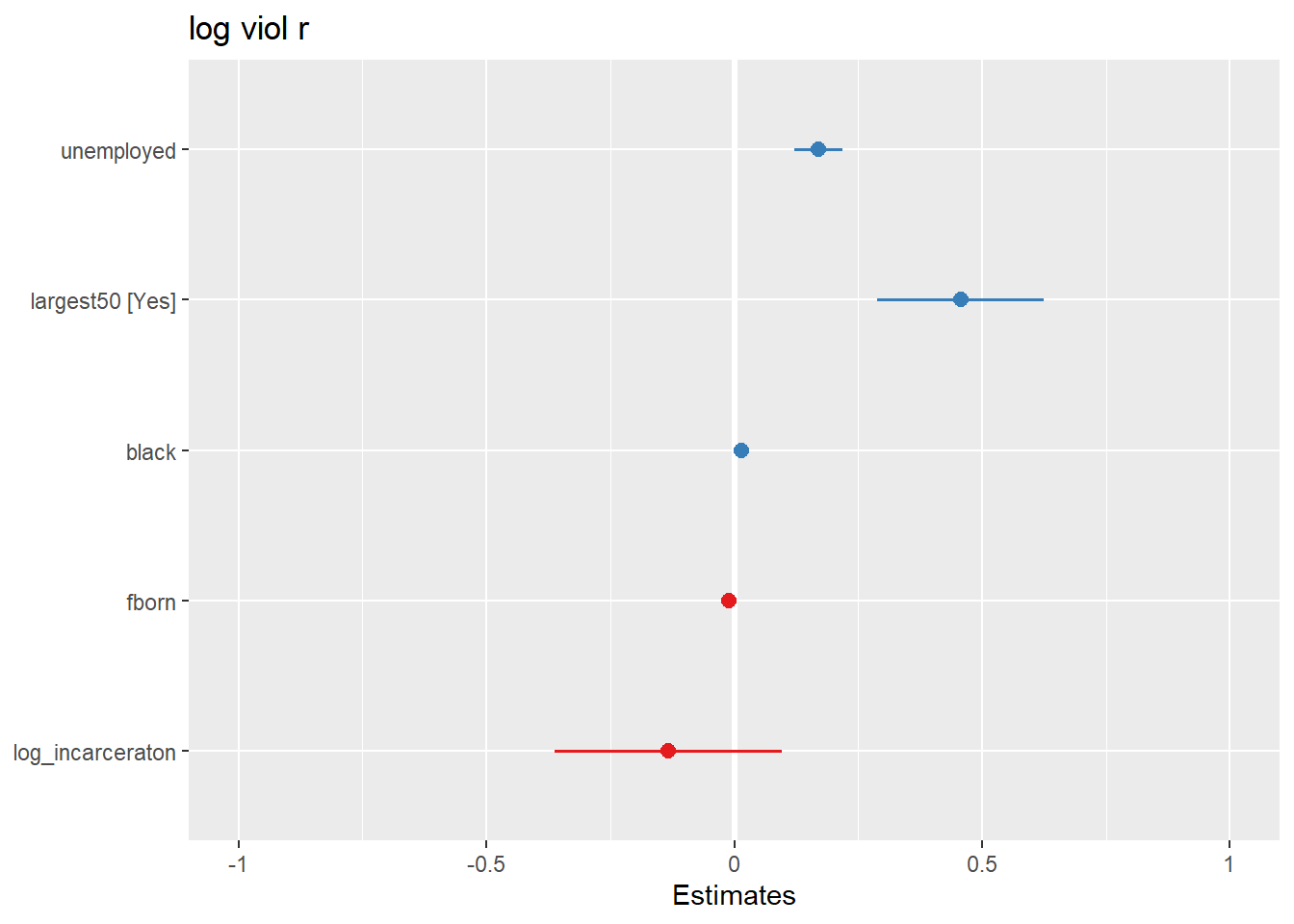
You can further customise this:
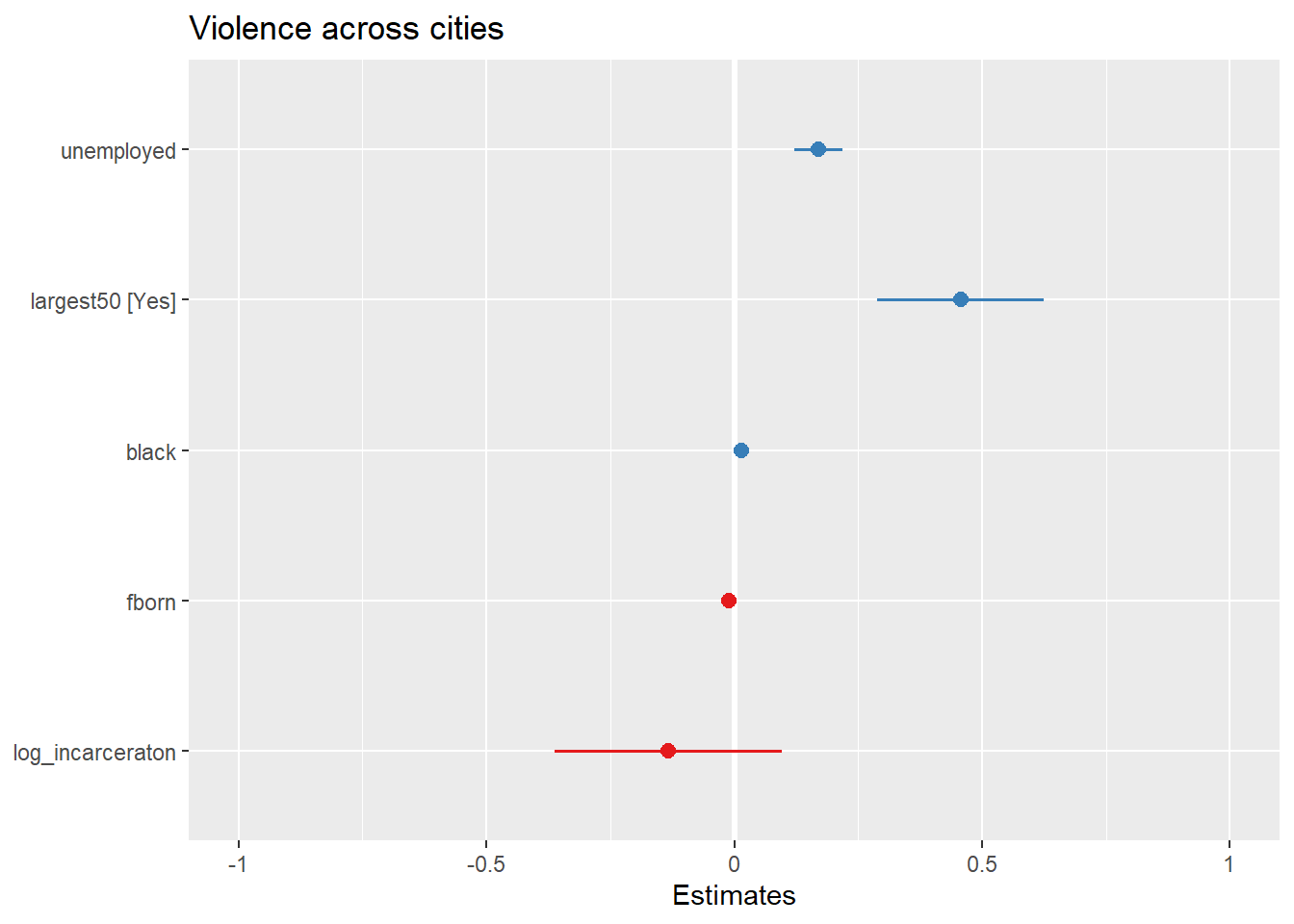
What you see plotted here is the point estimates (the circles), the confidence intervals around those estimates (the longer the line the less precise the estimate), and the colours represent whether the effect is negative (red) or positive (blue). There are other packages that also provide similar functionality, like the dotwhisker package that you may want to explore, see more details here.
The sjPlot package also allows you to produce html tables for more professional presentation of your regression tables. For this we use the tab_model() function. This kind of tabulation may be particularly helpful for your final assignment.
| log viol r | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 5.65 | 4.19 – 7.12 | <0.001 |
| unemployed | 0.17 | 0.12 – 0.22 | <0.001 |
| largest50 [Yes] | 0.46 | 0.29 – 0.63 | <0.001 |
| black | 0.02 | 0.01 – 0.02 | <0.001 |
| fborn | -0.01 | -0.02 – -0.00 | 0.001 |
| log_incarceraton | -0.13 | -0.36 – 0.10 | 0.251 |
| Observations | 263 | ||
| R2 / R2 adjusted | 0.508 / 0.499 | ||
As before you can further customise this table. Let’s change for example the name that is displayed for the dependent variable.
| Violence rate (log) | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 5.65 | 4.19 – 7.12 | <0.001 |
| unemployed | 0.17 | 0.12 – 0.22 | <0.001 |
| largest50 [Yes] | 0.46 | 0.29 – 0.63 | <0.001 |
| black | 0.02 | 0.01 – 0.02 | <0.001 |
| fborn | -0.01 | -0.02 – -0.00 | 0.001 |
| log_incarceraton | -0.13 | -0.36 – 0.10 | 0.251 |
| Observations | 263 | ||
| R2 / R2 adjusted | 0.508 / 0.499 | ||
Or you could change the labels for the independent variables:
| Violence rate (log) | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 5.65 | 4.19 – 7.12 | <0.001 |
| Percent unemployment | 0.17 | 0.12 – 0.22 | <0.001 |
| Largest cities (Yes) | 0.46 | 0.29 – 0.63 | <0.001 |
| Percent black | 0.02 | 0.01 – 0.02 | <0.001 |
| Percent foreign born | -0.01 | -0.02 – -0.00 | 0.001 |
| Incarceration rate (log) | -0.13 | -0.36 – 0.10 | 0.251 |
| Observations | 263 | ||
| R2 / R2 adjusted | 0.508 / 0.499 | ||
Visual display of the effects of the variables in the model are particularly helpful. The effects package allows us to produce plots to visualise these relationships (when adjusting for the other variables in the model). Here’s an example going back to our model fit_3 which contained unemployment and the dummy for large cities as predictor variables:
## Loading required package: carData## lattice theme set by effectsTheme()
## See ?effectsTheme for details.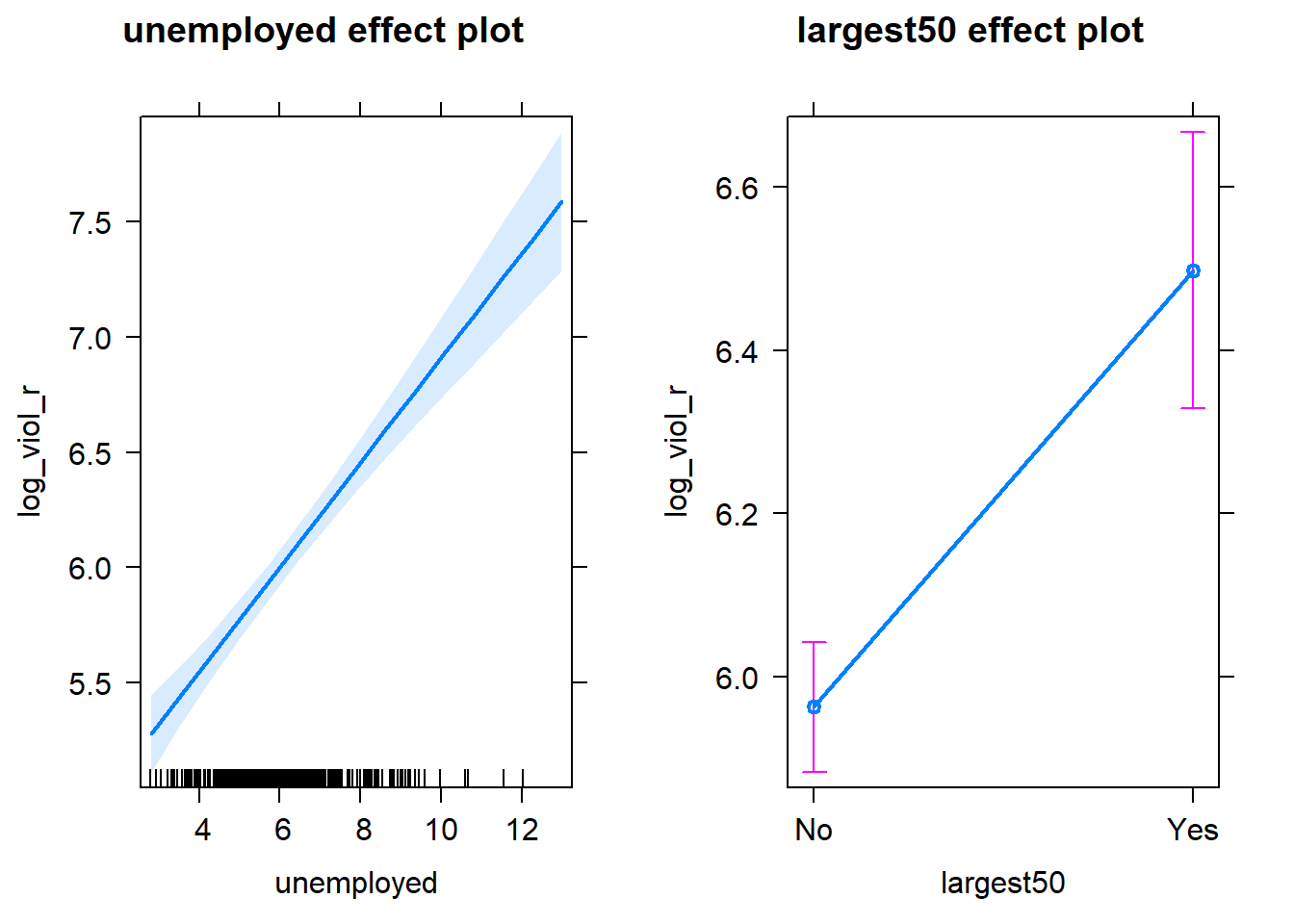
Notice that the line has a confidence interval drawn around it (to reflect the likely impact of sampling variation) and that the predicted means for smaller and largest cities (when controlling for unemployment) also have a confidence interval.
##Rescaling input variables to assist interpretation
The interpretation or regression coefficients is sensitive to the scale of measurement of the predictors. This means one cannot compare the magnitude of the coefficients to compare the relevance of variables to predict the response variable. Let’s look at the more recent model, how can we tell what predictors have a stronger effect?
##
## Call:
## lm(formula = log_viol_r ~ unemployed + largest50 + black + fborn +
## log_incarceraton, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.4546 -0.3523 -0.0009 0.3827 1.5771
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.654459 0.743725 7.603 5.44e-13 ***
## unemployed 0.169895 0.024496 6.936 3.27e-11 ***
## largest50Yes 0.457226 0.085311 5.360 1.86e-07 ***
## black 0.015003 0.002678 5.602 5.44e-08 ***
## fborn -0.010414 0.003101 -3.358 0.000904 ***
## log_incarceraton -0.133946 0.116461 -1.150 0.251158
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.523 on 257 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.5082, Adjusted R-squared: 0.4987
## F-statistic: 53.12 on 5 and 257 DF, p-value: < 2.2e-16We just cannot. One way of dealing with this is by rescaling the input variables. A common method involves subtracting the mean and dividing by the standard deviation of each numerical input. The coefficients in these models is the expected difference in the response variable, comparing units that differ by one standard deviation in the predictor while adjusting for other predictors in the model.
Instead, Gelman (2008) has proposed dividing each numeric variables by two times its standard deviation, so that the generic comparison is with inputs equal to plus/minus one standard deviation. As Gelman explains the resulting coefficients are then comparable to untransformed binary predictors. The implementation of this approach in the arm package subtract the mean of each binary input while it subtract the mean and divide by two standard deviations for every numeric input.
The way we would obtain these rescaled inputs uses the standardize() function of the arm package, that takes as an argument the name of the stored fit model.
##
## Call:
## lm(formula = log_viol_r ~ z.unemployed + c.largest50 + z.black +
## z.fborn + z.log_incarceraton, data = df)
##
## Coefficients:
## (Intercept) z.unemployed c.largest50 z.black
## 6.06080 0.56923 0.45723 0.49188
## z.fborn z.log_incarceraton
## -0.24890 -0.08133Notice the main change affects the numerical predictors. The unstandardised coefficients are influenced by the degree of variability in your predictors, which means that typically they will be larger for your binary inputs. With unstandardised coefficients you are comparing complete change in one variable (whether one is a large city or not) with one-unit changes in your numerical variable, which may not amount to much change. So, by putting in a comparable scale, you avoid this problem.
Standardising in the way described here will help you to make fairer comparisons. This standardised coefficients are comparable in a way that the unstandardised coefficients are not. We can now see what inputs have a comparatively stronger effect. It is very important to realise, though, that one should not compare standardised coefficients across different models.
8.10 Testing conditional hypothesis: interactions
In the social sciences there is a great interest in what are called conditional hypothesis or interactions. Many of our theories do not assume simply additive effects but multiplicative effects.For example, Wikstrom and his colleagues (2011) suggest that the threat of punishment only affects the probability of involvement on crime for those that have a propensity to offend but are largely irrelevant for people who do not have this propensity. Or you may think that a particular crime prevention programme may work in some environments but not in others. The interest in this kind of conditional hypothesis is growing.
One of the assumptions of the regression model is that the relationship between the response variable and your predictors is additive. That is, if you have two predictors x1 and x2. Regression assumes that the effect of x1 on y is the same at all levels of x2. If that is not the case, you are then violating one of the assumptions of regression. This is in fact one of the most important assumptions of regression, even if researchers often overlook it.
One way of extending our model to accommodate for interaction effects is to add additional terms to our model, a third predictor x3, where x3 is simply the product of multiplying x1 by x2. Notice we keep a term for each of the main effects (the original predictors) as well as a new term for the interaction effect. “Analysts should include all constitutive terms when specifying multiplicative interaction models except in very rare circumstances” (Brambor et al., 2006: 66).
How do we do this in R? One way is to use the following notation in the formula argument. Notice how we have added a third term unemployed:largest50, which is asking R to test the conditional hypothesis that the perceptions of antisocial behaviour may have a different impact on fear of violent crime for men and women.
fit_5 <- lm(log_viol_r ~ unemployed + largest50 + unemployed:largest50 , data=df)
# which is equivalent to:
# fit_5 <- lm(log_viol_r ~ unemployed * largest50, data=BCS0708)
summary(fit_5)##
## Call:
## lm(formula = log_viol_r ~ unemployed + largest50 + unemployed:largest50,
## data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.71844 -0.41330 -0.02989 0.45583 1.59625
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.49267 0.15636 28.734 <2e-16 ***
## unemployed 0.23532 0.02443 9.630 <2e-16 ***
## largest50Yes 0.83064 0.36794 2.258 0.0248 *
## unemployed:largest50Yes -0.04557 0.05479 -0.832 0.4063
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5919 on 260 degrees of freedom
## Multiple R-squared: 0.3673, Adjusted R-squared: 0.36
## F-statistic: 50.32 on 3 and 260 DF, p-value: < 2.2e-16You see here that essentially you have only two inputs (perceptions of the area and sex) but several regression coefficients. Gelman and Hill (2007) suggest reserving the term input for the variables encoding the information and to use the term predictor to refer to each of the terms in the model. So here we have two inputs and four predictors (one for the constant term, one for unemployment, another for the largest 50 dummy, and a final one for the interaction effect).
In this case the test for the interaction effect is non-significant, which suggests there isn’t such an interaction. The R squared barely changes. Let’s visualise the results with the effects package:
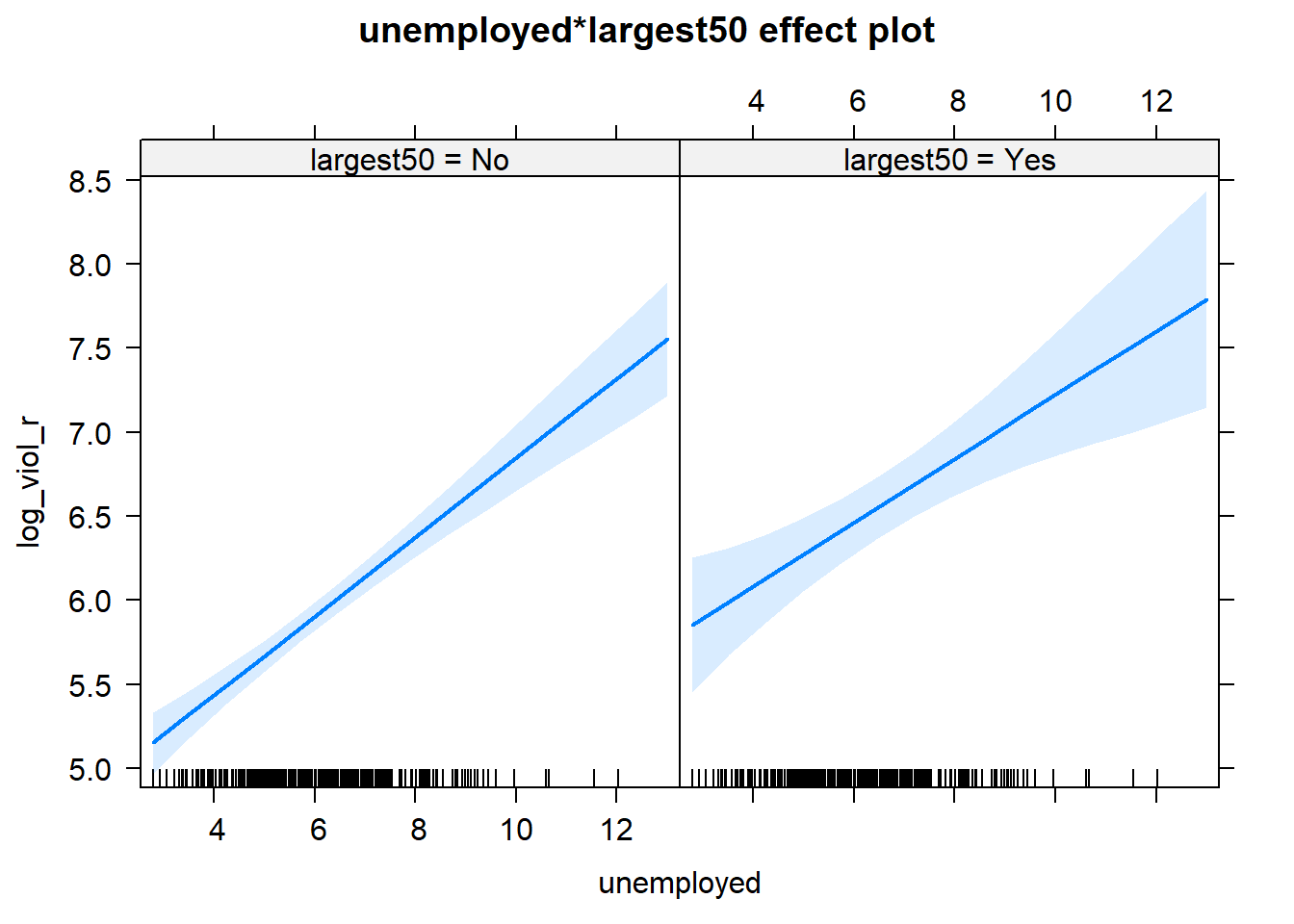
Notice that essentially what we are doing is running two regression lines and testing whether the slope is different for the two groups. The intercept is different, we know that largest cities are more violent, but what we are testing here is whether violence goes up in a steeper fashion (and in the same direction) for one or the other group as unemployment goes up. We see that’s not the case here. The estimated lines are almost parallel.
A word of warning, the moment you introduce an interaction effect the meaning of the coefficients for the other predictors changes (what it is often referred as to the “main effects” as opposed to the interaction effect). You cannot retain the interpretation we introduced earlier. Now, for example, the coefficient for the largest50 variable relates the marginal effect of this variable when unemployment equals zero. The typical table of results helps you to understand whether the effects are significant but offers little of interest that will help you to meaningfully interpret what the effects are. For this is better you use some of the graphical displays we have covered.
Essentially what happens is that the regression coefficients that get printed are interpretable only for certain groups. So now:
The intercept still represents the predicted score of violence for the smaller cities and have a score of 0 in unemployment (as before).
The coefficient of the largest50Yes predictor now can be thought of as the difference between the predicted score of violence for small cities that have a score of 0 in unemployment and largest cities that have a score of 0 in unemployment.
The coefficient of unemployed now becomes the comparison of mean violence for small cities who differ by one point in unemployment.
The coefficient for the interaction term represents the difference in the slope for unemployed comparing smaller and largest cities, the difference in the slope of the two lines that we visualised above.
Models with interaction terms are too often misinterpreted. I strongly recommend you read this piece by Brambor et al (2005) to understand some of the issues involved. When discussing logistic regression we will return to this and will consider tricks to ease the interpretation.
Equally, John Fox (2003) piece on the effects package goes to much more detail that we can here to explain the logic and some of the options that are available when producing plots to show interactions with this package. You may also want to have a look at the newer interactions package here.
8.11 Model building and variable selection
How do you construct a good model? This partly depends on your goal, although there are commonalities. You do want to start with theory as a way to select your predictors and when specifying the nature of the relationship to your response variable (e.g., additive, multiplicative). Gelman and Hill (2007) provide a series of general principles. I would like to emphasise at this stage two of them:
Include all input variables that, for substantive reasons, might be expected to be important in predicting the outcome.
For inputs with large effects, consider including their interactions as well.
It is often the case that for any model, the response variable is only related to a subset of the predictors. There are some scenarios where you may be interested in understanding what is the best subset of predictors. Imagine that you want to develop a risk assessment tool to be used by police officers that respond to a domestic violence incident, so that you could use this tool for forecasting the future risk of violence. There is a cost to adding too many predictors. A police officer time should not be wasted gathering information on predictors that are not associated with future risk. So you may want to identify the predictors that will help in this process.
Ideally, we would like to perform variable selection by trying out a lot of different models, each containing a different subset of the predictors. There are various statistics that help in making comparisons across models. Unfortunately, as the number of potentially relevant predictors increases the number of potential models to compare increases exponentially. So you need methods that help you in this process. There are a number of tools that you can use for variable selection but this goes beyond the aims of this introduction. If you are interested you may want to read this.
8.12 HOMEWORK
Fit a multiple regression model with at least 5 inputs to explain log_viol_r but use a different year from the dataset, say 2005. Use at least five explanatory variables.
Although we would like to think of our samples as random, it is in fact very difficult to generate random numbers in a computer. Most of the time someone is telling you they are using random numbers they are most likely using pseudo-random numbers. If this is the kind of thing that gets you excited you may want to read the wiki entry. If you want to know how R generates these numbers you should ask for the help pages for the Random.Seed function.↩
As an aside, you can use this Java applet to see what happens when one uses different parameters with confidence intervals. In the right hand side you will see a button that says “Sample”. Press there. This will produce a horizontal line representing the confidence interval. The left hand side end of the line represents the lower limit of the confidence interval and the right hand side end of the line represents the upper limit of the confidence interval. The red point in the middle is your sample mean, your point estimate. If you are lucky the line will be black and it will cross the green vertical line. This means that your CI covers the population mean. There will be a difference with your point estimate (i.e., your red point is unlikely to be just in top of the green vertical line). But, at least, the population parameter will be included within the range of plausible values for it that our confidence interval is estimating. If you keep pressing the “Sample” button (please do 30 or 50 times), you will see that most confidence intervals include the population parameter: most will cross the green line and will be represented by a black line. Sometimes your point estimate (the red point at the centre of the horizontal lines) will be to the right of the population mean (will be higher) or to the left (will be lower), but the confidence interval will include the population mean (and cross the green vertical line).↩
This is an interesting blog entry in solutions when you have highly skewed data.↩