Chapter 2 Causality in randomised experiments
2.2 Getting data thanks to reproducibility
Last week we introduced the notion of reproducible research and said that using and publishing code (particularly if using open source tools like R) is the way that many researchers around the world think that science ought to be done. This way of operating makes research more open, more credible, and more legitimate. It also means that we can more easily access the data used in published research. For this session we are going to use the data from this and this paper study. In this research project, the authors tried to answer the question of whether criminal antecedents and other personal characteristics have an impact on access to employment. You can find more details about this work in episode 8 of Probable Causation, the criminology podcast.
Amanda Agan and Sonja Starr developed a randomised experiment in which they created 15,220 fake resumes randomly generating these critical characteristics (such as having a criminal record) and used these resumes to send online job applications to low-skill, entry level job openings in New Jersey and New York City. All the fictitious applicants were male and about 21 to 22 years old. These kind of experiments are very common among researchers that want to explore through these “audits” whether some personal characteristics are discriminated against in the labor market.
Because Amanda Agan and Sonja Starr conformed to reproducible standards when doing their research we can access this data from the Harvard Dataverse (a repository for open research data). Click here to locate the data.
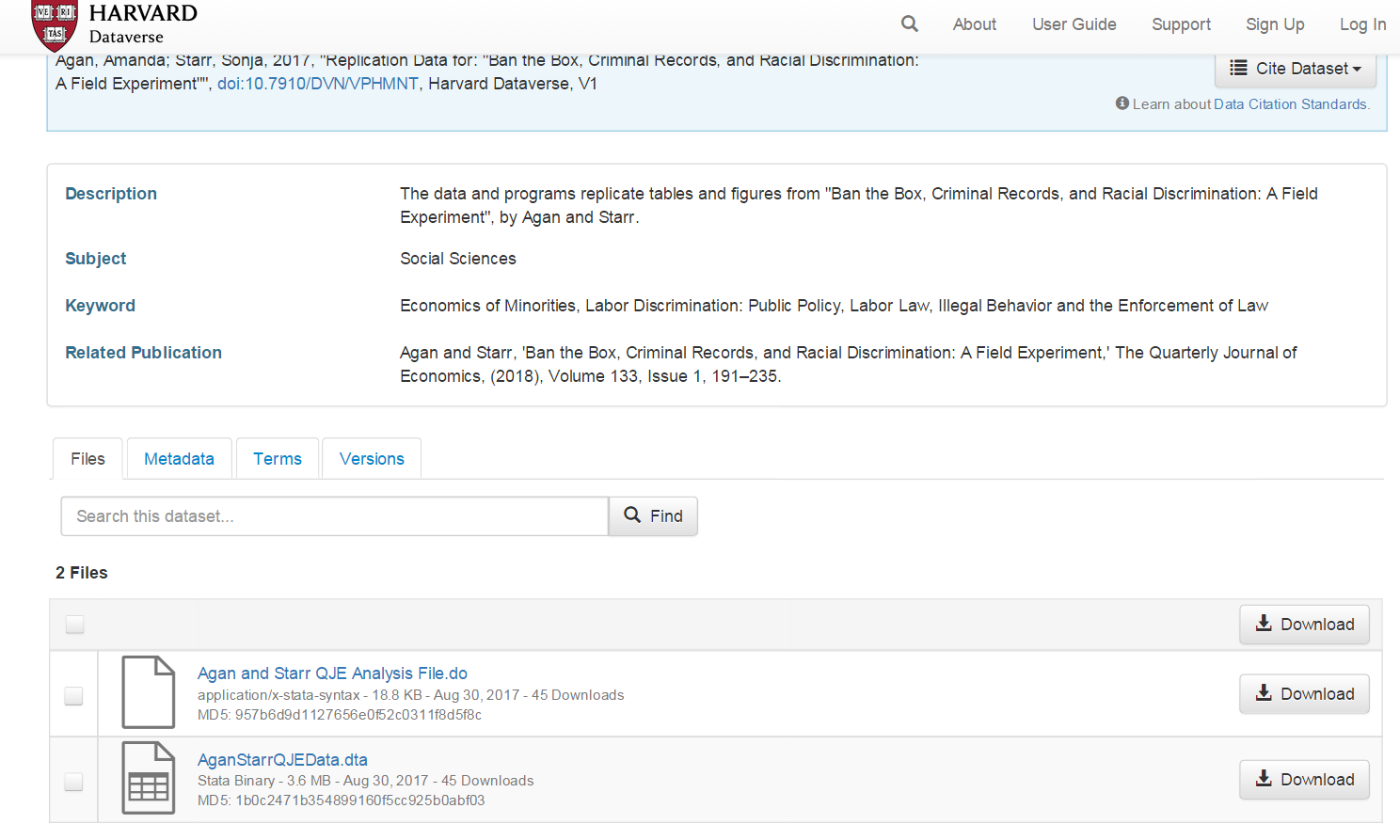
In this page you can see a download section and some files that can be accessed. One of them contains analytic code pertaining to the study and the other contains the data. You also see a link called metadata. Metadata is data about data, it simply provides you with some information about the data. If you clink in metadata you will see at the bottom a reference to the software the authors used (STATA). So we know these files are in STATA proprietary format. Let’s download the data file and then read the data into R.
You could just click “download” and then place the file in your project directory. Alternatively, and preferably, you may want to use code to make your whole work more reproducible. Think of it this way, every time you click or use drop down menus you are doing things that others cannot reproduce because there won’t be a written record of your steps. You will need though to do some clicking for finding out the required url you will use for writing your code. The file we want is the AganStarrQJEData.dta. Click in the name of this file. You will be taken to another webpage. On it you will see the download url. Copy and paste this url in your code below.
#First, let's create an object with the link, paste the copied address here:
data_url <- "https://dataverse.harvard.edu/api/access/datafile/3036350"This data file is a STATA .dta file in our working directory. To read STATA files we will need the haven package. This is a package developed for importing different kind of data files into R. If you don’t have it you will need to install it. And then load it.
library(haven)
#Now we can use the read_dta function, within this function we will
#pass an argument, url, specifying to the read_dta function the need to
#make a url connection. The url function takes as an argument the url
#we are using and that we encoded in the data_url object in our case.
banbox <- read_dta(url(data_url))2.3 Getting a sense for your data
2.3.1 First steps
What is the first thing you need to ask yourself when you look at a dataset? Data are often too big to look at the whole thing. It is almost always impossible to eyeball the entire dataset and see what you have in terms of interesting patterns or potential problems. It is often a case of information overload and we want to be able to extract what is relevant and important about it. But where do you start? Here you can find a brief but very useful overview put together by Steph de Silva. Read it before we carry on.

As Mara Averick (somebody you want to follow in twitter at @dataanndme if you want to be in top of R related resources) suggests this also makes for good relationship advice!
Here we are going to introduce a few functions that will help you to start making sense for what you have just downloaded. Summarising the data is the first step in any analysis and it is also used for finding out potential problems with the data. Regarding the latter you want to look out for: missing values; values outside the expected range (e.g., someone aged 200 years); values that seem to be in the wrong units; mislabeled variables; or variables that seem to be the wrong class (e.g., a quantitative variable encoded as a factor).
Lets start by the basic things you always look first in a datasets. You can see in the Environment window that banbox has 14813 observations (rows) of 62 variables (columns). You can also obtain this information using code. Here you want the DIMensions of the dataframe (the number of rows and columns) so you use the dim() function:
## [1] 14813 62Looking at this information will help you to diagnose whether there was any trouble getting your data into R (e.g., imagine you know there should be more cases or more variables). You may also want to have a look at the names of the columns using the names() function. We will see the names of the variables.
## [1] "nj" "nyc" "app_date_d"
## [4] "pre" "post" "storeid"
## [7] "chain_id" "center" "crimbox"
## [10] "crime" "drugcrime" "propertycrime"
## [13] "ged" "empgap" "white"
## [16] "black" "remover" "noncomplier_store"
## [19] "balanced" "response" "response_date_d"
## [22] "daystoresponse" "interview" "cogroup_comb"
## [25] "cogroup_njnyc" "post_cogroup_njnyc" "white_cogroup_njnyc"
## [28] "ged_cogroup_njnyc" "empgap_cogroup_njnyc" "box_white"
## [31] "pre_white" "post_white" "white_nj"
## [34] "post_remover_ged" "post_ged" "remover_ged"
## [37] "post_remover_empgap" "post_empgap" "remover_empgap"
## [40] "post_remover_white" "post_remover" "remover_white"
## [43] "raerror" "retail" "num_stores"
## [46] "avg_salesvolume" "avg_num_employees" "retail_white"
## [49] "retail_post" "retail_post_white" "percblack"
## [52] "percwhite" "tot_crime_rate" "nocrimbox"
## [55] "nocrime_box" "nocrime_pre" "response_white"
## [58] "response_black" "response_ged" "response_hsd"
## [61] "response_empgap" "response_noempgap"As you may notice, these names may be hard to interpret. If you open the dataset in the data viewer of RStudio (using View) you will see that each column has a variable name and underneath a longer and more meaningful variable label that tells you what each variable means.
2.3.2 On tibbles and labelled vectors
You also want to understand what the banbox object actually is. You can do that using the class() function:
## [1] "tbl_df" "tbl" "data.frame"What does tbl stands for? It refers to tibbles. This is essentially a new type of data structure introduced into R. Tibbles are data frames, but a particular type. Not all data frames we encounter in R are tibbles.
The R language has been around for a while and sometimes things that made sense a couple of decades ago, make less sense now. A number of programmers are trying to create code that is more modern and more useful today. They are doing this by introducing a set of packages that speak to each other in order to modernise R without breaking existing code. You can think of it as an easier and more efficient modern dialect of R. This set of packages is called the tidyverse. Tibbles are dataframes that have been optimised to be used with this new set of packages. You can read a bit more about tibbles here.
You can also look at the class of each individual column. As discussed, class of the variable lets us know, for example, if its an integer (number), character, or factor.
To get the class of one variable, you pass it to the class() function. For example:
## [1] "haven_labelled"## [1] "numeric"We talked about numeric vectors in week one. It is simply a collection of numbers. But what is a labelled vector? This is a new type of vector introduced by the haven package. Labelled vectors are categorical variables that have labels. Go to the Environment panel and left click in the banbox object. This should open the data browser in the top left quadrant of RStudio.
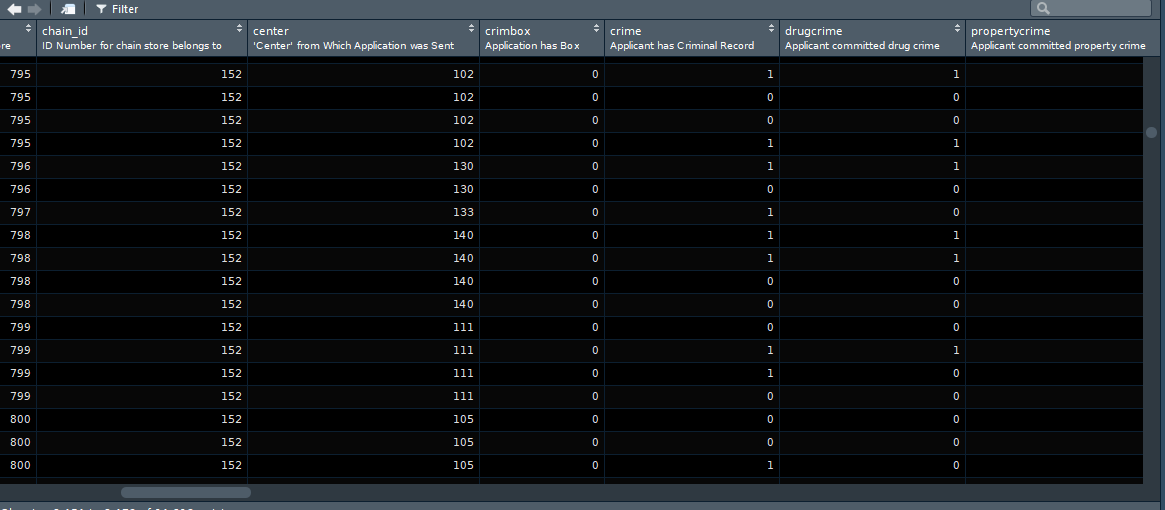
If you look carefully you will see that the various columns that include categorical variables only contain numbers. In many statistical environments, such as STATA or SPSS, this is a common standard. The variables have a numeric value for each observation and then each of these numeric values is associated with a label. This kind of made sense when computer memory was an issue - for this was an efficient way of saving resources. It also made manual data input quicker. These days it makes perhaps less sense. But labelled vectors give you a chance to reproduce data from other statistical environments without losing any fidelity in the import process. See what happens if we try to summarise this labelled vector. We will use the table() to provide a count of observations on the various valid values of the crime variable. It is a function to obtain your frequency distribution.
##
## 0 1
## 7323 7490So, we see that we have 7490 observations classed as 1 and 7323 classed as 2. If only we knew what those numbers represent! Well, we actually do. We will use the attributes() function to see the different “compartments”" within your “box”, your object.
## $label
## [1] "Applicant has Criminal Record"
##
## $format.stata
## [1] "%9.0g"
##
## $class
## [1] "haven_labelled"
##
## $labels
## No Crime Crime
## 0 1So this object has different compartments. The first one is called label and it provides a description of what the variable measures. This is what you saw in the RStudio data viewer earlier. The second compartment explains the original format in which it was. The third one identifies the class of the vector. Whereas the final one, labels, provides the labels that allows us to identify what the meaning of 0 and 1 mean in this context.
2.3.3 Turning variables into factors and changing the labels
Last week we said that many R functions expect factors when you have categorical data, so typically after you import data into R you may want to coerce your labelled vectors into factors. To do that you need to use the as_factor() function of the haven package. Let’s see how we do that.
#This code asks R to create a new column in your banbox tibble
#that is going to be called crime_f. Typically, when you alter
#variables you can to create a new one so that the original gets
#preserved in case you do something wrong. Then we use the
#as_factor() function to explain to R that what we want to do
#is to get the original crime variable and mutate it into
#a factor, this resulting factor is what will be stored in
#the new column.
banbox$crime_f <- as_factor(banbox$crime)You will see now that you have 63 variables in your dataset, look at the environment to check. Let’s explore the new variable we have created (you can also look for the new variable in the data browser and see how it looks different to the original crime variable):
## [1] "factor"##
## No Crime Crime
## 7323 7490## $levels
## [1] "No Crime" "Crime"
##
## $class
## [1] "factor"
##
## $label
## [1] "Applicant has Criminal Record"So far we have a looked at single columns in your dataframe one at the time. But there is a way that you can apply a function to all elements of a vector (list or dataframe). You can use the functions sapply(), lapply(), and mapply() . To find out more about when to use each one see here.
For example, we can use the lapply() function to look at each column and get its class. To do so, we have to pass two arguments to the lapply() function, the first is the name of the dataframe, to tell it what to look through, and the second is the function we want it to apply to every column of that function.
So we want to type “lapply(” + “name of dataframe” + “,” + “name of function” + “)”
Which is:
As you can see many variables are classed as labelled. This is common with survey data. Many of the questions in social surveys measure the answers as categorical variables (e.g., these are nominal or ordinal level measures). In fact, with this dataset there are many variables that are encoded as numeric that really aren’t. Welcome to real world data, where things can be a bit messy and need tidying!
See for example the variable black:
## [1] "numeric"##
## 0 1
## 7406 7407We know that this variable measures whether someone is black or not. When people use 0 and 1 to code binary responses, typically they use a 1 to denote a positive response, a yes. So, I think it is fair to assume that a 1 here means the respondent is black. Because this variable is of class numeric we cannot simply use as_factor to assign the pre-existing labels and create a new factor. In this case we don’t have preexisting labels, since this is not a labelled vector. So what can we do to tidy this variable? We’ll we need to do some further work.
#We will use a slightly different function as.factor()
banbox$black_f <- as.factor(banbox$black)
#You can check that the resulting column is a factor
class(banbox$black_f)## [1] "factor"#But if you print the frequency distribution you will see the
#data are still presented in relation to 0 and 1
table(banbox$black_f)##
## 0 1
## 7406 7407#You can use the levels function to see the levels, the
#categories, in your factor
levels(banbox$black_f)## [1] "0" "1"So, all we have done is create a new column that is a factor but still refers to 0 and 1. If we assume (rightly) that 1 mean black we have 7407 black applicants. Of course, it makes sense we only get 0 and 1 here. What else could R do? This is not a labelled vector, so there is no way for R to know that 0 and 1 mean anything other than 0 and 1, which is why those are the levels is using. But now that we have the factor we can rename those levels. We can use the following code to do just that:
#We are using the levels function to access them and change
#them to the levels we specify with the c() function. Be
#careful here, because the order we specify here will map
#out to the order of the existing levels. So given that 1 is
#black and black is the second level (as shown when printing
#the results above) you want to make sure that in the c()
#you write black as the second level.
levels(banbox$black_f) <- c("White", "Black")
table(banbox$black_f)##
## White Black
## 7406 7407This gives you an idea of the kind of transformations you often want to perform to make your data more useful for your purposes. But let’s keep looking at functions you can use to explore your dataset.
2.3.4 Looking for missing data and other anomalies
You can, for example, use the head() function if you just want to visualise the values for the first few cases in your dataset. The next code for example ask for the values for the first two cases. If you want a different number to be shown you just need to change the number you are passing as an argument.
In the same way you could look at the last two cases in your dataset using tail():
It is good practice to do this to ensure R has read the data correctly and there’s nothing terribly wrong with your dataset. If you have access to STATA you can open the original file in STATA and check if there are any discrepancies, for example. Glimpsing your data in this way can also give you a first impression for what the data looks like.
One thing you may also want to do is to see if there are any missing values. For that we can use the is.na() function. Missing values in R are coded as NA. The code below, for example, asks for NA values for the variable response_black in the banbox object for observations 1 to 10:
## [1] FALSE TRUE TRUE FALSE FALSE TRUE TRUE TRUE FALSE TRUEThe result is a logical vector that tells us if it is true that there is missing (NA) data for each of those first ten observations. You can see that there are 6 observations out of those 10 that have missing values for this variable.
## [1] 7406This is asking R to sum how many cases are TRUE NA in this variable. When reading a logical vector as the one we are creating, R will treat the FALSE elements as 0s and the TRUE elements as 1s. So basically the sum() function will count the number of TRUE cases returned by the is.na() function.
You can use a bit of a hack to get the proportion of missing cases instead of the count:
## [1] 0.4999662This code is exploiting the mathematical fact that the mean of binary outcomes (0 or 1) gives you the proportion of ones in your data. As a rule of thumb, if you see more than 5% of the cases declared as NA, you need to start thinking about the implications of this. Beware of formulaic application of rules of thumb such as this though! In this case, we know that 49%% of the observations have missing values in this variable. When you see things like this the first thing to do is to look at the codebook or documentation to try to get some clues as to why there are so many missing cases. With survey data you often have questions that are simply not asked to everybody, so it’s not necessarily that something went very wrong with the data collection, but simply that the variable in question was only used with a subset of the sample. And that, therefore, any analysis you do using this question will only relate to that particular subset of cases.
There is a whole field of statistics devoted to doing analysis when missing data is a problem. R has extensive capabilities for dealing with missing data -see for example here. For the purpose of this introductory course, however, we only explain how to do analysis that ignore missing data. This is often referred to a full/complete case analysis, because you only use observations for which you have full information in all the variables you employ. You would cover techniques for dealing with this sort of issues in more advanced courses.
2.4 Data wrangling with dplyr
The data analysis workflow has a number of stages. The diagram below (produced by Hadley Wickham) is a nice illustration of this process:
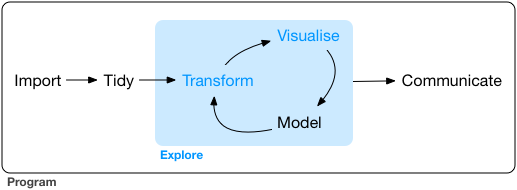
We have started to see different ways of bringing data into R. And we have also started to see how we can explore our data. It is now time we start discussing one of the following stages, transform. A good deal of time and effort in data analysis is devoted to this. You get your data and then you have to do some transformations to it so that you can answer the questions you want to address in your research. We have already seen, for example, how to turn variables into factors, but there are other things you may want to do.
R offers a great deal of flexibility in how to transform your data, Here we are going to illustrate some of the functionality of the dplyr package for data carpentry (a term people use to refer to this kind of operations). This package is part of the tydiverse and it aims to provide a friendly and modern take on how to work with dataframes (or tibbles) in R. It offers, as the authors of the package put it, “a flexible grammar of data manipulation”.
Dplyr aims to provide a function for each basic verbs of data manipulation:
*filter()*to select cases based on their values.*arrange()*to reorder the cases.*select()*and*rename()*to select variables based on their names.*mutate()*and*transmute()*to add new variables that are functions of existing variables.*summarise()*to condense multiple values to a single value.*sample_n()*and*sample_frac()*to take random samples.
In this session we will introduce and practice some of these. But we won’t have time to cover everything. There is, however, a very nice set of vignettes for this package in the help files, so you can try to go through those if you want a greater degree of detail or more practice.
Now let’s load the package:
##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionNotice that when you run this package you get a series of warnings in the conseole. It is telling us that some functions from certain packages are being “masked”. One the things with a language like R is that sometimes packages introduce functions that have the same name than others that are already loaded into your session. When that happens the newly loaded ones will over-ride the previous ones. You can still use them but you will have to refer to them explicitly. Otherwise R will assume you are using the function most recently loaded:
#Example:
#If you use load dplyr and then invoke the *filter()* function
#R will assume you are using the filter function from dplyr
#rather than the *filter()* function that exist in the *stats*
#package, which is part of the basic installation of R. If
#after loading dplyr you want to use the filter function from
#the stats package you will have to invoke it like this:
stats::filter()
#Notice the grammar, first you write the name of the package,
#then colon twice, and then the name of the function. Don't
#run this code. You would need to pass some valid arguments
#for this to produce meaningful results.2.5 Using dplyr single verbs
One of the first operations you may want to carry out when working with dataframes is to subset them based on values of particular variables. Say we want to replicate the results reported by Agan and Starr in 2017. In this earlier paper, these researchers only used data from the period prior to the introduction of Ban the Box legislation and only used data from businesses that asked about criminal records in their online applications. How can we recreate this dataset?
For this kind of operations we use the filter() function. Like all single verbs in dplyr, the first argument is the tibble (or data frame). The second and subsequent arguments refer to variables within that data frame, selecting rows where the expression is TRUE.
Ok, so if we look at the dataset we can see that there is a variable called “crimbox” that identifies applications that require information about criminal antecedents and there is a variable called “pre” that identifies whether the application was sent before the legislation was introduced. In this dataset the value 1 is being used to denote positive responses. So, if we want to create the 2017 dataset we would start by selecting only data where the value in these two variables equals 1 as shown below.
#We will store the results of filtering the data in a new
#object that I am calling aer (short for the name of the
#journal in which the paper was published)
aer2017<- filter(banbox, crimbox == 1, pre == 1)Notice that the number of cases equals the number of cases reported by the authors in their 2017 paper. That’s cool! So far we are replicating with same results.
You may have noticed in the code above that I wrote “==”" instead of “=”. Logical operators in R are not written exactly the same way than in normal practice. Keep this in mind when you get error messages from running your code. Often the source of your error may be that you are writing the logical operators the wrong way (as far as R is concerned). Look here for valid logic operators in R.
Sometimes you may want to select only a few variables. Earlier we said that real life data may have hundreds of variables and only a few of those may be relevant for your analysis. Say you only want “crime”, “ged” (a ged is a high school equivalence diploma rather than a proper high school diploma and is sometimes seen as inferior), “empgap” (a gap year on employment), “black_f”, “response”, and “daystoresponse” from this dataset. For this kind of operations you use the select() function.
The syntax of this function is easy. First we name the dataframe object (“aer2017”) and then we list the variables. The order in which we list the variables within the select function will determine the order in which those columns appear in the new dataframe we are creating. So this is a handy function to use if you want to change the order of your columns for some reason. Since I am pretty confident I am not making a mistake I will transform the original “aer2017” tibble rather than creating an entirely new object.
If you now look at the global environment you will see that the “aer2017” tibble has reduced in size and now only has 6 columns. If you view the data you will see these are the 6 variables we selected.
2.6 Using dplyr for grouped operations
So far we have used dplyr single verbs for ungrouped operations. But we can also use some of the functionality of dplyr for obtaining answers to questions that relate to groups of cases within our dataframe. Imagine that you want to know if applicants with a criminal record are less likely to receive a positive response from employers. How could you figure that one out? For answering this kind of questions we can use the group_by() function in conjunction with other dplyr functions. In particular we are going to look at the summarise function.
First we group the observations by criminal record in a new object, by using as_factor in the call to the crime variable the results will be labelled later on (even though we are not changing the crime variable in the aer2017 dataframe. Keep in mind we are using as_factor because the column crime is a labelled vector rather than a factor or a character vector, and we do this to aid interpretation (it is easier to interpret labels than 0 and 1).
by_antecedents <- group_by(aer2017, as_factor(crime))
#Then we run the summarise function to provide some useful
#summaries of the groups we are using: the number of cases
#and the mean of the response variable
results <- summarise(by_antecedents,
count = n(),
outcome = mean(response, na.rm = TRUE))
#autoprint the results stored in the newly created object
results## # A tibble: 2 x 3
## `as_factor(crime)` count outcome
## <fct> <int> <dbl>
## 1 No Crime 1319 0.136
## 2 Crime 1336 0.0846Let’s look at the code in the summarise function above. First we are asking R to place the results in an object we are calling “results”. Then we are specifying that we want to group the data in the way we specified in our group_by() function before, that is by criminal record. Then we pass two arguments. Each of these arguments is creating a new variable in the resulting object called “results”. The first variable we are creating is called “count” by saying this equals “n()” we are specifying to R that this new variable simply counts the number of cases in each of the grouping categories. The second variable we are creating is called “outcome” and to compute this variable we are asking R to compute the mean of the variable response for each of the two groups of applicants defined in “by_antecedents” (those with records, those without). Remember that the variable response in the “aer2017” dataframe was coded as numeric variable, even though in truth is categorical in nature (there was a response, or not, from the employers). It doesn’t really matter. Taking the mean of a binary variable in this case is mathematically equivalent to computing a proportion as we discussed earlier.
So, what we see here is that about 13.6% of applicants with no criminal record received a positive response from the employers, whereas only 8% of those with criminal records did receive such a response. Given that the assignation of a criminal record was randomised to the applicants, there’s a pretty good chance that no other confounders are influencing this outcome. And that is the beauty of randomised experiments. You may be in a position to make stronger claims about your results.
HOMEWORK 1: Use what we have learned so far to see if there is an interaction effect between race and criminal records. That is, what would happen if we compare 4 groups: whites with no records, whites with records, blacks with no records, and blacks with records. What do you think? Is there an interaction effect? In other words, is the impact of having a criminal record more accentuated for either of the two racial groups?
2.7 Making comparisons with numerical outcomes
We have been looking at relationships so far between categorical variables, specifically between having a criminal record (yes or no), race (black or white), and receiving a positive response from employers (yes or no). Often we may be interested in looking at the impact of a factor on a numerical outcome. In the banbox object we have such an outcome measured by the researchers. The variable “daystoresponse” tells us how long it took the employers to provide a positive response. Let’s look at this variable:
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 3.00 10.00 19.48 28.00 153.00 14361The summary() function provides some useful stats for numerical variables. We obtain the minimum and maximum value, the 25th percentile, the median, the mean, the 75th percentile, and the number of missing data (NA). You can see the number of missing data here is massive. Most cases have missing data on this variable. Clearly this is a function of, first and foremost, the fact that the number of days to receive a positive response will only be collected in cases where there was a positive response! But even accounting for that, it is clear that this information is also missing in many cases that received a positive response. So given all of this, we need to be very careful when interpreting this variable. Yet, because it is the only numeric variable here we will use it to illustrate some handy functions.
We could do as before and get results by groups. Let’s look at the impact of race on days to response:
by_race <- group_by(banbox, black_f)
results_3 <- summarise(by_race,
avg_delay = mean(daystoresponse, na.rm = TRUE))
results_3## # A tibble: 2 x 2
## black_f avg_delay
## <fct> <dbl>
## 1 White 18.7
## 2 Black 20.4Homework 2:
Answer the following questions:
2.1 What is a tibble?
2.2 How is a variable name different from a variable label?"
2.3 What is a labelled vector?
How is the filter() function different from the select() function?
Homework 3:
For this course unit you need to write a coursework assignment in which you will use data from a social survey to explore relationships between various variables. Specifically, you will be allowed to use. So you will need to pick one of them and then select a topic (of those listed below) to explore with each of these surveys:
- The 2018 wave of the European Social Survey, which you can access here and explore here. From this dataset you will be able to explore the following topic: "victimisation in the last 5 years (crmvct)
- The 2013-2014 Crime Survey for England and Wales (the Teaching Dataset version) which you can access here or explore here. From this dataset you will need to focus on one of the following topics “fairness of criminal justice system (fairx)”, “confidence in the police in their neighbourhood (confx)”, or “worry about being a victim of crime (worryx)”.
As part of this week homework you need to let us know which survey and which topic you want to focus on for your coursework assignment.
You can explore the datasets and what other variables are available. For your coursework you will need to identify other variables in these surveys that you think may be associated or helpful to understand why people vary in worry of crime, confidence towards the police, etc. At this point you don’t need to identify those other variables, but you may find it useful to explore what’s available in those datasets using NESSTAR (a guide for how to use NESSTAR is available here and the existing documentation for those studies